文|周鑫雨
編輯|鄧詠儀
2024年5月,互聯網大模型率先迎來“618”。
制圖:周鑫雨
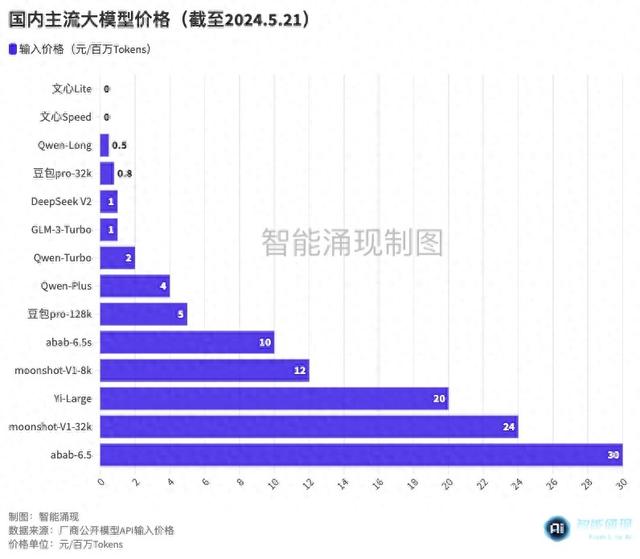
其中,阿裏雲商業化的主力大模型Qwen-Long,輸入價格降幅甚至達到了97%,價格從原有的20元/百萬Tokens,直降爲0.5元/百萬Tokens。
這一價格,以0.0003元/千Tokens的微妙優勢,擊穿了5月15日字節剛剛公布的“豆包大模型”的輸入地板價:0.8元/百萬Tokens。
然而,低價之王剛易位4小時,百度就前來“掀翻了價格地板”——文心一言兩款模型ERNIE Speed和ERNIE Lite,直接宣布“免費”。
在2023年,模型的降價仍然遵從著訓練效率優化和規模效應的自然趨勢。
2023年11月,百度的大模型平台“文心千帆”,曾經調整了相同漢字數量對應的Token數,變相將模型的價格降低了20%。與之對應地,是文心大模型的推理成本降低到了原來的1%。
但2024年的模型價格戰,開打得幾乎毫無預兆。
價格斷崖的開端,是一條名爲“DeepSeek V2”的鲶魚。DeepSeek的出品機構“深度求索”的背後,是坐擁過萬張英偉達A100 GPU的量化基金——幻方量化。
5月6日,深度求索發布了DeepSeek大模型的新版本V2。作爲模型領域的“黑馬”,2360億參數規模的DeepSeek V2,模型性能處于國産第一梯隊,定價也沒有什麽包袱,支持32k上下文的模型API定價僅1元/百萬Tokens(計算)、2元/百萬Tokens(推理),是彼時百度文心4.0-8k推理價格(120元/Tokens)的1/60。

制圖:周鑫雨
此後,大模型獨角獸智譜AI率先加入了價格戰。5月11日,智譜AI旗下的GLM-3-Turbo,價格從5元/百萬Tokens,降低到了1元/Tokens。
“黑馬”攪局模型定價的另一面,則是更具性價比的小模型被重提。
不少從業者對智能湧現表示,小模型的潛力還沒被完全發掘,完全可以通過數據治理、效率優化等策略,以小博大,這對于下遊客戶而言也是更有性價比的選擇。
2024年4月22日,Meta發布的開源模型Llama-3,就以70B的“小參數”,和超過20倍參數量的GPT-4在性能上掰手腕。緊接著,微軟又發布了3.8B的模型Phi-3 mini,號稱性能對標GPT-3.5,還能在蘋果A16芯片上流暢運行。
對于下遊客戶而言,昂貴的大模型不夠“香了”。大廠大模型的集體降價,也是在順應市場選擇。
不過,即便是價格砸穿地板,大廠們依然有利可圖。大模型只是門面,大廠的漁翁之意,是通過模型賣自己的雲服務。
以擁有自己的計算集群的幻方量化爲例,據SemiAnalysis計算,在其算力服務力利用率最高的情況下,DeepSeek每台服務器每小時收益可達35.4美元,毛利率在70%以上。
但對于被迫卷入價格戰的小廠商和初創公司而言,營收的壓力將會更大。2024年5月21日,零一萬物CEO李開複就直言,不參與價格戰,最新模型Yi-Large的API定價仍爲20元/百萬Tokens。
未來,小廠們唯有在單點或多點性能上和競爭對手們拉開差距,才能分到蛋糕。

歡迎交流!
歡迎交流!

分個毛線 AI沒錢就會被抛棄[吃瓜]