得益于微軟的新人工智能技術,蒙娜麗莎現在可以做的不僅僅是展示神秘的微笑了。
微軟的研究人員公布並詳細介紹了他們開發的一種新的人工智能模型——VASA-1。

微軟公布新AI模型VASA-1
它可以將一張靜態的人臉圖像和某人說話的音頻片段結合,創建出一個看起來能以假亂真的視頻。
這些視頻中,原本靜態的人像會根據音頻內容、詞彙和語義情感,展現出逼真的嘴唇同步和自然的面部表現,甚至是在適當的時候,微揚的眉毛、上翹的嘴角或彎彎的眼角細節,在說話的過程中,頭部還會有自然的擺動幅度。

AI能讓蒙娜麗莎唱RAP
這一切,讓視頻內容看起來很有欺騙性,仿佛就是由主角在親口講述內容一般。
除了普通人像照片,AI還可以利用名畫或卡通插圖等來匹配語音內容生成視頻。比如,研究人員展示了他們如何讓蒙娜麗莎背誦美國女演員安妮海瑟薇的喜劇說唱。
來自VASA-1的輸出,既有趣又有點不真實,它學習了大量的人們說話時的面部視頻,現階段,已能基本識別自然的面部表情和頭部運動,包括“嘴唇弧度,眼神和眨眼、揚眉等等”。
微軟表示,該技術可用于教育方面,或“改善有溝通障礙的個人的社交狀況”,或爲孤獨人群創造出完美擬真的虛擬伴侶。
若是仔細觀察VASA-1輸出的視頻,仍然能從中找到AI生成的蛛絲馬迹,例如有些時候,略顯僵硬的眨眼和誇張的眉毛運動等。
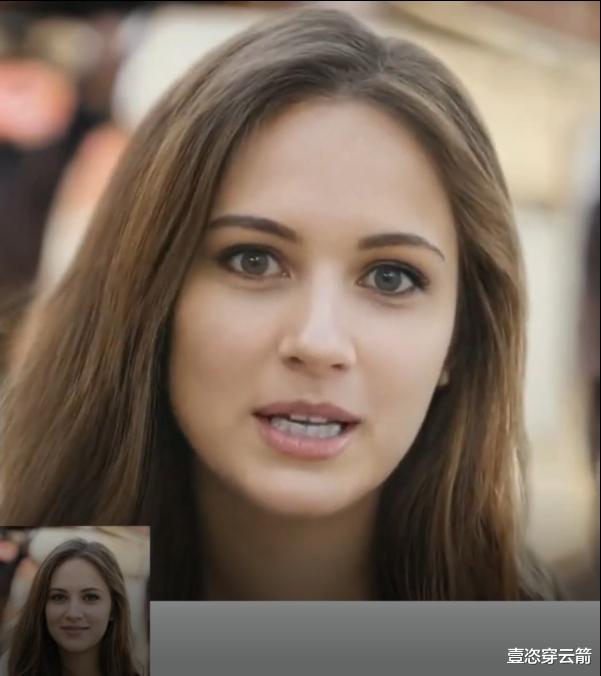
AI根據小姐姐照片生成了她說話的視頻
但微軟表示,它相信自己的模型“明顯優于”其他類似的工具,並“爲與模仿人類對話行爲的逼真化身進行實時互動鋪平了道路”。
在公衆驚歎的同時,也傳出了擔憂的聲音,有民衆認爲,這項AI技術如果缺乏監管,它可以很容易的被濫用來冒充真實的人。還有些從事廣告或電影行業的專業人士也表示了擔心,認爲這項技術可能會進一步擾亂以創意爲主的人工産業。
目前,微軟表示不打算向公衆發布VASA-1模型,只提供給一些專業用戶和網絡安全教授用于測試目的。
微軟研究人員在一篇博客文章中說:“我們反對任何冒用真實的人的名義發出誤導或有害內容的行爲。”他補充說,公司目前“沒有計劃公開發布”該産品,“直到我們確定該技術將被負責任地使用,並符合適當的規定。
