隨著大數據時代的到來,數據處理和分析已經成爲每個數據科學家和數據分析師的必備技能。然而,面對日益增長的數據量和複雜性,傳統的數據處理工具已經難以滿足需求。在這個背景下,Polars 應運而生,它憑借高性能、易用性和開源特性,迅速成爲數據分析領域的新寵。本文將從多個角度全面介紹 Polars,幫助您深入了解這個強大的 DataFrame 庫。
 Polars 簡介
Polars 簡介Polars 是一個高性能的 DataFrame 庫,專爲數據分析和機器學習任務設計。它采用 Rust 編程語言編寫,充分利用了現代 CPU 的多核性能和高速緩存一致性。與傳統的 Python DataFrame 庫(如 pandas)相比,Polars 在處理大規模數據集時具有顯著的性能優勢。
 Polars 的設計哲學
Polars 的設計哲學Polars 的設計哲學圍繞著高效、簡潔和可擴展性展開。它致力于:
充分利用計算資源:通過並行計算和優化查詢,確保每一分計算資源都得到充分利用。減少不必要的開銷:優化數據結構和算法,降低內存分配和計算複雜度。適應大數據時代:提供處理遠超內存容量的大數據集的能力,滿足現代數據分析的需求。提供一致的 API 體驗:無論數據類型如何變化,Polars 的 API 始終保持一致和可預測。 Polars 的核心特點極致性能:Polars 從底層開始構建,充分利用 Rust 的高性能和內存安全特性,確保在處理大量數據時保持高速和穩定。多平台支持:無論您習慣使用 Python、R 還是 NodeJS,Polars 都能爲您提供無縫銜接的數據處理體驗。全面的 I/O 支持:Polars 支持所有常見的數據存儲格式,無論是本地文件、雲存儲還是數據庫,都能輕松應對。直觀的 API 設計:Polars 的 API 簡潔明了,讓您能夠專注于數據分析本身,而無需擔心底層的實現細節。核外處理能力:借助流式 API,Polars 允許您在數據不完全加載到內存的情況下進行處理,大大降低了內存消耗。並行計算與向量化引擎:Polars 充分利用現代 CPU 的多核性能和 SIMD 指令集,實現查詢的高效執行。高性能背後的技術多線程查詢引擎:Polars 的多線程查詢引擎能夠充分利用 CPU 的多核性能,實現數據的並行處理。這意味著在執行複雜的查詢操作時,Polars 可以更快地完成任務。向量化列式處理:Polars 采用向量化列式處理方法,將數據按列存儲和處理。這種方法不僅提高了數據處理的效率,還有助于減少內存占用。優化的執行計劃:Polars 內置了查詢優化器,能夠根據查詢的具體情況自動選擇最優的執行計劃。這確保了在執行查詢時能夠最大限度地利用計算資源。
Polars 的核心特點極致性能:Polars 從底層開始構建,充分利用 Rust 的高性能和內存安全特性,確保在處理大量數據時保持高速和穩定。多平台支持:無論您習慣使用 Python、R 還是 NodeJS,Polars 都能爲您提供無縫銜接的數據處理體驗。全面的 I/O 支持:Polars 支持所有常見的數據存儲格式,無論是本地文件、雲存儲還是數據庫,都能輕松應對。直觀的 API 設計:Polars 的 API 簡潔明了,讓您能夠專注于數據分析本身,而無需擔心底層的實現細節。核外處理能力:借助流式 API,Polars 允許您在數據不完全加載到內存的情況下進行處理,大大降低了內存消耗。並行計算與向量化引擎:Polars 充分利用現代 CPU 的多核性能和 SIMD 指令集,實現查詢的高效執行。高性能背後的技術多線程查詢引擎:Polars 的多線程查詢引擎能夠充分利用 CPU 的多核性能,實現數據的並行處理。這意味著在執行複雜的查詢操作時,Polars 可以更快地完成任務。向量化列式處理:Polars 采用向量化列式處理方法,將數據按列存儲和處理。這種方法不僅提高了數據處理的效率,還有助于減少內存占用。優化的執行計劃:Polars 內置了查詢優化器,能夠根據查詢的具體情況自動選擇最優的執行計劃。這確保了在執行查詢時能夠最大限度地利用計算資源。 易用性體驗
易用性體驗盡管 Polars 具有高性能的技術特點,但它的使用門檻卻非常低。Polars 的 API 設計簡潔明了,易于上手。無論是數據清洗、轉換還是聚合操作,Polars 都能提供直觀且高效的實現方式。此外,Polars 還提供了豐富的文檔和示例代碼,幫助用戶快速掌握使用方法。
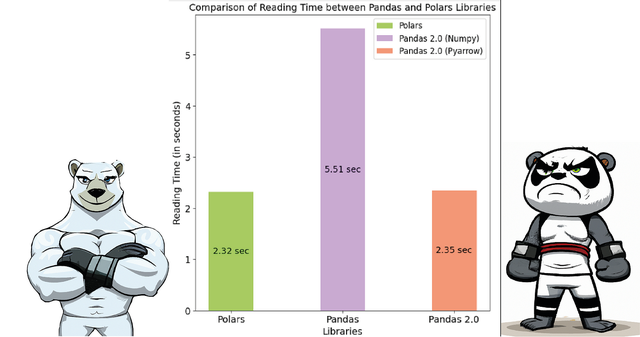 開源與社區支持
開源與社區支持作爲一款開源軟件,Polars 得到了全球開發者社區的熱情支持和貢獻。這意味著在使用過程中,您可以隨時在社區中尋求幫助、分享經驗、參與討論甚至貢獻代碼。這種開放和包容的氛圍使得 Polars 得以持續發展和完善,爲用戶帶來更好的使用體驗。
 與其他工具的集成
與其他工具的集成在數據科學和機器學習的工作流程中,往往需要使用多種不同的工具和庫。幸運的是,Polars 具有良好的兼容性,能夠與其他流行的數據處理和機器學習庫無縫集成。例如,您可以使用 Polars 與 NumPy、Pandas 等其他庫進行數據交互;同時,Polars 也支持與 Scikit-learn、TensorFlow 等機器學習框架結合使用,爲您的數據分析項目提供更強大的功能支持。
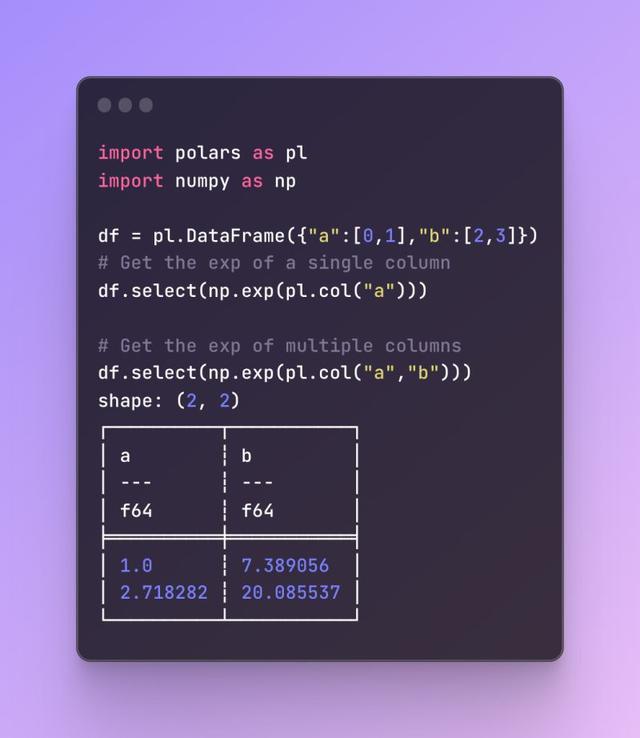 總結與展望
總結與展望綜上所述,Polars 以其高性能、易用性、開源特性和廣泛的兼容性成爲了數據分析新時代的利器。無論您是數據科學家、數據分析師還是機器學習工程師,Polars 都將成爲您不可或缺的助手。展望未來,我們期待 Polars 在更多領域發揮潛力,推動數據處理和分析技術的進步與發展。希望通過本文的介紹和分析,您能夠更好地了解並掌握這款優秀的 DataFrame 庫,從而在未來的工作中更加遊刃有余地應對各種挑戰和需求。
