
編輯 | GenAICon 2024
2024中國生成式AI大會于4月18-19日在北京舉行,在大會首日的主會場大模型專場上,前Meta首席工程負責人胡魯輝老師以《從多模態大模型到理解物理世界》爲題發表演講。
胡魯輝談道,聚焦多模態大模型的後GPT-4時代呈現出4大趨勢,一是語言大模型到多模態大模型,二是數據集成到向量數據庫,三是Agent智能體到大模型操作系統,四是模型微調到Plugin(插件)平台。
他認爲大模型是通向AGI靠譜的方法。在大模型的落地應用中,企業和研究機構需要面對多方面的挑戰。首先是數據的標准化問題,不同來源和格式的數據需要被轉化成一種統一的格式,以便于模型的訓練和應用。
此外,模型的分散性和應用場景的複雜性也大大增加了開發的難度。例如,在不同的物理環境下,模型需要調整其參數以適應特定的硬件和軟件條件。同時,算力成本和訓練時間的長短也是制約大模型廣泛應用的重要因素。
胡魯輝預測下一個AI 2.0爆發點及落地大方向將是AI for Robotics。這一領域的發展需要模型不僅理解編程或語言處理,更要深入到物理世界的具體應用中去。這涉及對物理環境的理解和設計,需要大模型能夠整合各種感知數據,進行快速的決策和學習,以應對不斷變化的外部條件。這一過程中,模型的訓練和應用將更加依賴于高效的算力和先進的硬件支持。
以下爲胡魯輝的演講實錄:
今天我要分享的是《從多模態大模型到理解物理世界》。大模型的快速發展加上不斷的技術演變,變化很大,我希望將自己的一些實戰經曆分享給大家。
今天主要分享4個方面。首先從大模型的原理出發,講一下GPT-4之後硅谷及全球有哪些重大變化;其次結合大模型和多模態的特征,分享Transformer以及我在Meta的相關工作經曆;今天的重點是爲什麽要去理解物理世界,僅僅依靠語言大模型並不能走向通用人工智能,理解物理世界才有可能走向它;最後,結合多模態大模型和理解物理世界探討如何接近AGI。
一、大模型開啓AI 2.0時代,Meta是開源領導者每個技術的快速發展離不開背後大量的科研創新工作,這是人工智能複興的原因,因爲其在快速發展和叠代。人工智能的重要性和意義十分突出,可以說,這次人工智能是第四次計算時代或第四次工業革命。第三次計算時代是移動互聯網時代,我們正處于這個時代,根據每次的發展,第四次的規模比第三次要大,且從經濟效益上來講,對人類社會的影響力更大。
人工智能在曆史上有兩個拐點,AlphaGo和ChatGPT。雖然每一個拐點只代表一個産品或者技術,但其對人類的影響不僅是技術本身,如AlphaGo,不可能所有公司都做下棋産品或平台。對社會來說,第一次是利用拐點背後的技術(如CV或別的技術)開始AI 1.0時代。這一次則是基于大模型泛化湧現的能力開始AI 2.0時代。
ChatGPT發布了一年多,性能表現的排名仍比較領先。並且現在大模型訓練的費用或成本越來越高,之前GPT-4訓練的時候需要6000萬美元左右,GPT-5可能更貴。

目前OpenAI是閉源大模型的領導者,Meta是開源的領導者。OpenAI在閉源大模型中的領導地位是公認的,Meta的開源大模型Llama和視覺SAM比較領先。其中Llama幫助了很多語言模型開發公司的團隊,讓他們擁有了很好的基礎。
現在模型中,有三個閉源和三個開源比較領先。或許大家疑惑Meta的Llama怎麽不見了,Meta在做另外一件更有意義的事情,就是理解物理世界,他們叫世界模型。最近Llama還沒有叠代,大家可以拭目以待,這個排名還是會變化的,Llama爲很多大語言模型奠定了基礎,幫助很多企業飛速發展。

Meta的視覺大模型還有很多貢獻。Transformer最初應用于語言模型,逐步衍生到視覺,其中比較火的一個就是ViT,視覺Transformer。
Meta通過ViT或Transformer不斷叠代,有三個影響比較大的視覺Transformer:一是DeTr,Detection Transformer,它有端到端的Object Detection;二是DINO,通過Transformer開啓了視覺領域的自監督,無論是大語言模型還是其他大模型,都不能依賴打標簽,需要它能夠自主學習監督;三是SAM,更多是零樣本,是泛化的能力。

在視覺領域,除了Sora,SAM影響力較大。怎麽訓練SAM,需要多少資源,或者訓練過程中需要注意哪些事情?我去年寫了一篇文章Fine-tune SAM,詳細講了怎麽利用SAM做微調,如何控制資源,或者利用資源更有效地做微調。

幾年前,一提到人工智能,就會想到視覺、語言兩個支派,CNN、RNN基本上井水不犯河水。做NLP的一波人和做CV的那波人有各自的學術派,方法不一樣,會議也不太一樣。這次深度學習,語言模型從LSTM到Word2Vec,到最近的GPT還有BERT。視覺模型最早從分類到檢測,再到分割,接著從語義分割到實例分割。
這裏有許多地方特別相近,所謂的語言大模型無非是更深層次的一個相關性和邏輯推理。視覺也是一樣,邏輯上二者是融合的,技術上是Transformer。語言層面GPT-4、 Llama比較經典;視覺中Sora和SAM都是比較經典的例子,它後面的Backbone都是基于Transformer。
無論從邏輯上講語義相關性,還是技術上Transformer Backbone,都在逐步融合。
這是一個好消息。對研發工作者而言,以前井水不犯河水的NLP和CV終于有一天融合了。它在發生一個質的變化。
當前AI的核心技術,也是個比較靠譜的AGI方法,能從一個技術、一個方向擴展到下一階段。但Meta首席AI科學家楊立昆反而不這麽認爲,JEPA從最初的Image JEPA到Video JEPA有自己的理論。但不管怎麽樣,從工程上或者應用上,它的效果確實突出。
打造大模型的核心關鍵能力是什麽?一般人會說是三個核心,數據、算力、算法。而我根據一些工作經驗還歸納出來另外兩點。
一個是模型架構,現在的大模型和以前的深度學習算法不同的地方,就是模型架構的重要性。通過Backbone或模型架構的重塑做遷移學習或微調,不是僅僅把領域數據或者領域知識輸入進去,而是通過改變模型架構産生一個新的模型,達到自己想要的領域模型。
還有一個是智能工程。Llama是開源的,OpenAI搞出來GPT-3.5,也就是ChatGPT,改變世界的奇點就發生了。有GPT-3,有數據、算力,但能不能制造出GPT-3.5?不同的公司不一樣,根本原因就是智能工程不同。
這五個裏面哪個最核心、最關鍵?很多人可能會說是算力,很貴,買不到H100、A100,但是無論是谷歌還是微軟,都不會缺乏算力,他們目前卻沒有世界最領先的GPT-4這樣的模型。
國內很喜歡說數據,沒有數據的確很難搞出好的模型,但是很多大廠也不會缺數據。算法基本上是開源的,像Transformer或者一些比較新的算法也是開源的,它也不是最關鍵因素。而模型架構,也可以通過一些微調、不同的嘗試探索出來。
所以結合國外的模型和國內的現狀,最核心打造大模型的能力應該是智能工程。
這也就是說OpenAI的一些人出來創業搞Claude,剛才大家看到排名中第二領先的就是Claude,就是OpenAI中的人出來創業做的事情。說明人才是最值錢的。
三、預測“後GPT-4”四大發展趨勢,理解物理世界有七大特征現在GPT-4是多模態大模型,在硅谷及全球人工智能發展到底有哪些趨勢?我認爲有四個方面,這張圖是根據我的預測讓GPT-4生成的圖例展示。

第一,從語言大模型到多模態大模型。
第二,邁向向量數據庫。目前的大語言模型或多模態大模型不論多大,都有一定的局限性,導致向量數據庫火起來了。大家可以把一部分或大部分的數據放在向量數據庫裏,把相關的數據放在大模型中。
第三,從自動Agent到將大模型作爲操作系統。Agent比較火,但是它的背後依然是語言大模型或多模態大模型。Agent相當于軟件自動實現。後續多模態大模型作爲操作系統可能是比較核心的。
第四,開源模型從微調到引入插件平台。ChatGPT相當于一個平台,不僅可以微調,而且可以通過插件作爲一個平台,因此插件可能是未來的一個方向。

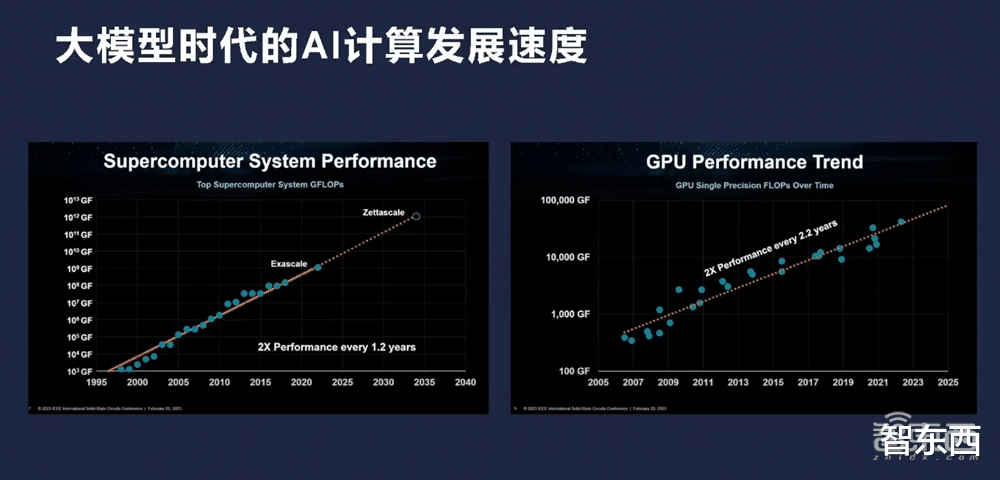
爲什麽模型能夠這麽快發展,爲什麽我們能夠支撐Scaling Law?很大原因是計算能力的發展。CPU時代有摩爾定律,GPU時代同樣發展速度更快。去年英偉達發布能夠支撐1億FLOPS的算力,今年他們發布了新的DGX GB200,去年是GH200,現在是GB200,小了一點,更快一點,但還是一個量級的。好幾個DGX串起來是很大的規模,近十年之前IBM計算機也是相當大的,而現在手機就能支撐以前的算力,GPU其實也一樣。
有這個大模型或算力後,應用在發生什麽變化?可以看到,AI 2.0比較以前的傳統軟件或互聯網,用戶和場景可能都一樣。但是以前是用戶從App到服務軟件再到CPU,現在是用戶從多模態到基礎模型,然後到GPU,中間可以依賴數據庫或者訓練數據,傳統的用數據庫,現在用向量數據庫。
接下來關于理解物理世界,AI賦能了智能手機、智能車、智能家居等等,圍繞的計算核心是智能雲。現在或未來中心會是AI factory(人工智能工廠),它的輸入是Token,文字、視覺或視頻,它的輸出就是AI。過去應用有手機、有車,將來就是各種機器人。未來汽車某種意義上也是一種機器人。從架構來看,AI for Robotics是一個未來方向,未來即將爆發的方向,從雲計算、AI工程、基礎模型,生成式AI再到上面的AI for Robotics。
理解物理世界也比較有挑戰性,現在的語言模型只能局限于訓練的範圍中,對外界的理解還是有相當的局限性。

理解物理世界到底有哪些特征,怎麽能夠從現有的多模態大模型轉向理解物理世界,有了理解物理世界以後再向AGI接近?我認爲有七個方面,最外面的紫色是比較優秀的人,因爲人的水平都不一樣,作爲比較優秀的人能夠理解物理世界的水平。

但GPT-4或最新的GPT-4 Turbo是什麽樣?是裏面的圈。現在GPT-4 Turbo和人還是有很大的距離,只有從每個維度提升發展,才能真正理解物理世界,更加接近地通用人工智能。
理解物理世界不僅僅是對空間的理解或者空間智能,因爲從概念上 “空間”相當于3D,不包括語言等核心AI。
說到這裏,大家可能覺得比較抽象,這也是Meta最近在做的一些事情。Meta在開源大模型或者開源多模態大模型方面目前顯得“落後”了,但Llama 3馬上來了,是因爲它把很多精力花在了世界模型中,同時在治理的7個方面提高模型的能力。
我最近成立一家公司叫智澄AI,致力于通用人工智能。“澄”的意思是逐步走向真正的智能。
以上是胡魯輝老師演講內容的完整整理。
