
第一作者:Manu Suvarna
通訊作者:Javier Pérez-Ramírez
通訊單位:蘇黎世聯邦理工學
論文速覽
本文綜述了數據科學在催化研究中的應用,強調了催化劑發現和開發對全球能源、可持續性和醫療保健需求的重要性。過去十年中,數據科學概念在催化研究中的利用顯著增加,以幫助解決這些問題。
文章全面回顧了催化研究者如何利用數據驅動策略解決多相、均相和酶催化中的複雜挑戰。研究者將所有研究分爲演繹型或歸納型模式,並統計推斷催化任務、模型反應、數據表示和算法選擇的普遍性。
文章突出了該領域的前沿和催化子學科之間的知識遷移可能性。關鍵評估揭示了實驗催化中數據科學探索的明顯差距,並通過詳細闡述數據科學的四個支柱(即描述性、預測性、因果性和規範性分析)彌合這一差距。
文章提倡將這些分析方法納入常規實驗工作流程,並強調數據標准化對未來數字催化研究的重要性。

圖文導讀

圖1:展示了過去十年數據驅動催化研究的增長趨勢,特別是從2018年開始的指數增長。圖中將催化問題解決使用機器學習(ML)的方法分類爲演繹型和歸納型兩種通用模式,其中演繹型任務旨在篩選或優化催化性能,而歸納型任務則側重于通過描述符或活性位點識別來得出機理見解。

圖2:網絡圖映射了基于催化類型(a)和驅動力(b)的演繹任務之間的關系。圖中的節點表示顯著實體的出版物計數,包括催化類型、驅動力、任務和數據源,節點之間的弧長與出版物之間的相互關系頻率成正比。

圖3:總結了催化領域主要的開源數據庫,根據催化類型、數據源和它們所引發任務進行分類,並展示了這些數據庫對FAIR(可發現、可訪問、可互操作和可重用)原則的遵循程度。

圖4:通過ML建立結構-屬性-性能關系的圖譜,展示了多相(a)、均相(b)和酶催化(c)中用于建立結構-屬性關系的ML算法的使用情況。

圖5:展示了催化中先進的AI框架,包括從文獻中提取合成程序和催化屬性的語言模型(a),主動學習用于探索特定催化劑的化學空間(b),使用GANs和VAEs等深度學習模型進行假想合金和配體的虛擬生成(c),以及深度強化學習用于優化催化表面或反應網絡(d)。
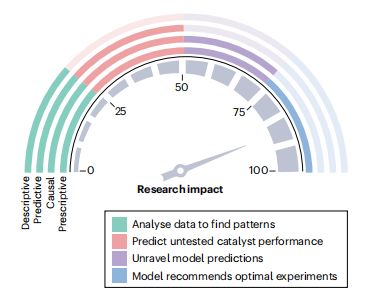
圖6:數據驅動催化的四個支柱示意圖,包括描述性分析、預測性分析、因果性分析和規範性分析。

圖7:展示了數據驅動催化的生命周期,包括描述性、預測性、因果性和規範性分析在實驗催化工作流程中的應用。

圖8:展示了將ML算法與表征工具集成的最新進展,包括深度學習在透射電子顯微鏡圖像分析中用于自動化原子檢測(a),以及結合XANES光譜學和ML方法用于改進多相催化劑的3D幾何結構(b)。
總結展望
文章強調了數據科學和機器學習(ML)在催化研究中的前景,預示著這些技術將極大提高研究生産力。同時指出,盡管這些技術不會取代人類的直覺和專業知識,但它們應該被催化研究者們接受,並成爲每個從業者工具箱的一部分。 文章呼籲催化從業者發展對數據驅動概念和建模策略的基礎理解,並熟悉數據准備、算法適用性評估及其優勢和局限性。同時,也鼓勵數據科學家培養對催化的欣賞,有效地將催化過程的複雜性轉化爲數據科學問題,並理解實驗限制。 文章展望了一個未來,其中數字工具無縫集成到催化研究中,加速實驗設計、數據分析和新知識的創造,促進數據驅動的決策制定,助力解決催化研究中的一些重大挑戰。
文獻信息
標題:Embracing data science in catalysis research 期刊:Nature Catalysis .
