當下機器學習和人工智能蓬勃發展的使python語言成了香饽饽。但是在涉及大量數值計算時候,需要我們使用一些“數學”化的技巧(算法)才能達到簡潔而高效的結果。本文蟲蟲就給大家介紹一種比較通用的這種技巧,即矢量化計算。矢量化計算可以替代數值計算中的循環操作,尤其是在進行大規模數的時候。
概述關于矢量化?矢量化是在數據集上實現 (NumPy) 數組運算的技術。在底層的算法中,通過使用線性代數中的矩陣運算可以一次性將操作應用于數組或所有列表對象(與一次操作一行的“for”循環不同)。本文我們將簡單介紹幾個常見計算用例,分別用循環和矢量化兩種方法進行計算,對比起消耗時間。
求和首先,我們將看一個在 Python 中使用循環和向量化求數字和的基本示例,隨機生成150萬個數字,對其求和:
循環算法
import time
start = time.time()
total = 0
for item in range(0, 1500000):
total = total + item
print('sum is:' + str(total))
end = time.time()
print(end - start)

矢量化方法
import numpy as np
start = time.time()
print(np.sum(np.arange(1500000)))
end = time.time()
print(end - start)

矢量化的執行時間減少了約18倍與使用range函數的叠代相比。 在使用Pandas DataFrame時,這種差異將變得更加顯著。
數據框操作在數據科學中,在使用數據框時,開發人員使用循環通過數學運算創建新的派生列。在下面的示例中可以輕松地將循環運算矢量化。
基本操作創建數據框
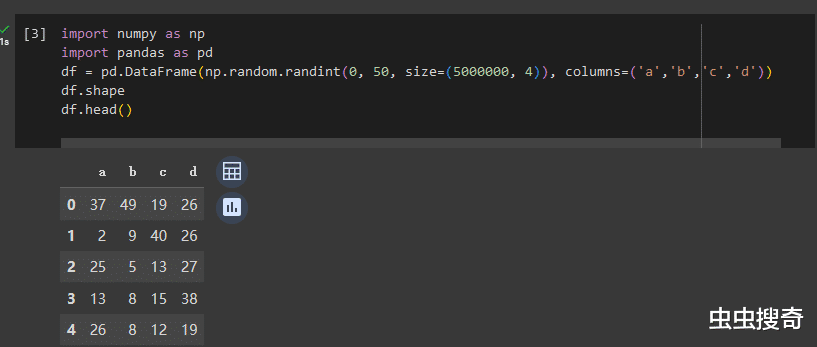
數據框(DataFrame)是行和列形式的表格數據,比如創建一個包含500萬行,a,b,c,d爲標頭4列的數據框,並對其用0-50的隨機數賦值。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 50, size=(5000000, 4)), columns=('a','b','c','d'))
df.shape
df.head()
將創建一個新列“ratio”來查找“d”列和“c”列的比率。
循環方法
import time
start = time.time()
for idx, row in df.iterrows():
# creating a new column
df.at[idx,'ratio'] = 100 * (row["d"] / row["c"])
end = time.time()
print(end - start)

結果用了6分多鍾
矢量方法
start = time.time()
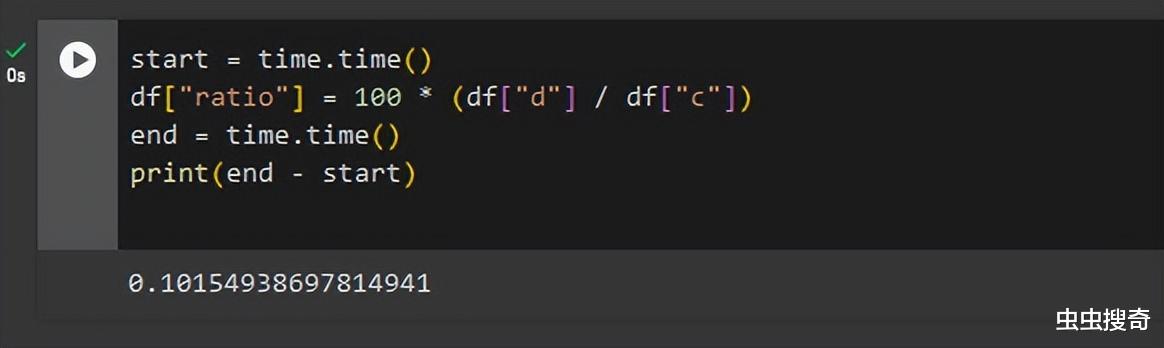
可以返現DataFrame情況下,兩種方法耗時存指數級明顯差異,循環方式慢的幾乎無法讓人接受,而矢量化方法耗時僅用0.1秒。
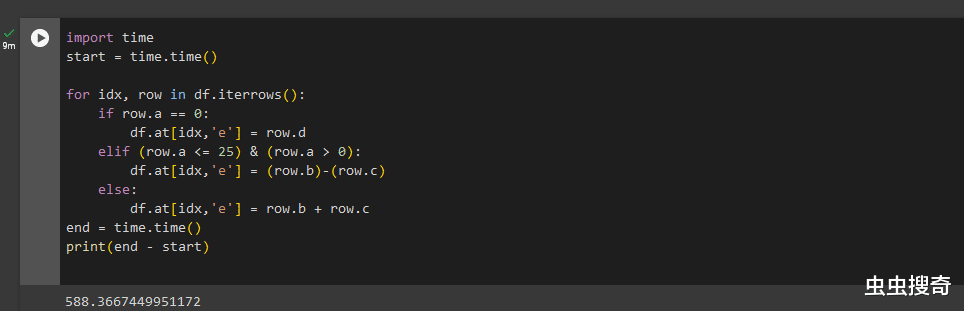
數據框If-else實現的許多操作需要使用“If-else”類型的邏輯,可以輕松地將這些邏輯替換爲矢量化操作。下面的例子中沿用上面創建的DataFrame),假設現在要求列“a”的某些條件創建一個新列“e”。
使用循環
import time
start = time.time()
for idx, row in df.iterrows():
if row.a == 0:
df.at[idx,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[idx,'e'] = (row.b)-(row.c)
else:
df.at[idx,'e'] = row.b + row.c
end = time.time()
print(end - start)
矢量化方法
start = time.time()
df['e'] = df['b'] + df['c']
df.loc[df['a'] <= 25, 'e'] = df['b'] -df['c']
df.loc[df['a']==0, 'e'] = df['d']
end = time.time()
print(end - start)

與循環方法相比矢量化操作所花費的時間快了近1700多倍
機器學習問題深度學習要求我們解決多個複雜的方程,並且需要解決數百萬和數億行的問題。在Python中運行循環來求解這些方程非常慢,矢量化則是適合的解決方案。例如,要計算以下多元線性回歸方程中數百萬行的y值:
Y= M1X1 + M2X2 + M3X3 + M4X4+ M5X5 + C
這類問題也可以用矢量化代替循環。m1,m2,m3…的值是通過使用與x1,x2,x3…對應的數百萬個值求解上述方程來確定的(爲簡單起見,只實現一個簡單的乘法步驟)
首先創建數據
import numpy as np
m = np.random.rand(1,5)

x = np.random.rand(5000000,5)
循環方法
import numpy as np
m = np.random.rand(1,5)
x = np.random.rand(5000000,5)
total = 0
start = time.process_time()
cc=np.zeros(5000000,dtype=float)
for i in range(0,5000000):
total = 0
for j in range(0,5):
total = total + x[i][j]*m[0][j]
cc[i]=total
end = time.process_time()
print (end-start)

矢量化方法
該方法在矢量計算中實際上就是幾個矢量的點積,熟悉線代同學應該都知道其計算原理,不了解同學可以看下圖理解:

start = time.process_time()
np.dot(x,m.T)
end = time.process_time()
print (start-end)

np.dot在後端實現矢量化矩陣乘法,比循環方法快了255倍。
總結
在Python數值計算中需要處理非常大的數據集時,Python 中的矢量化可以簡化代碼和極大的提高計算性能,矢量化計算可以作爲一個通用的算法進行普遍使用,這對提高Python的計算非常有意義,而這種“數學化”編程思路也值得廣泛采納和使用。
