
作者 | GenAICon 2024
2024中國生成式AI大會于4月18-19日在北京舉行,在大會第二天的主會場AI Infra專場上,阿裏雲高級技術專家、阿裏雲異構計算AI推理團隊負責人李鵬以《AI基礎設施的演進與挑戰》爲題發表演講。
李鵬談道,大模型的發展給計算體系結構帶來了功耗牆、內存牆和通訊牆等多重挑戰。其中,大模型訓練層面,用戶在模型裝載、模型並行、通信等環節面臨各種現實問題;在大模型推理層面,用戶在顯存、帶寬、量化上面臨性能瓶頸。
對于如何進一步釋放雲上性能?阿裏雲彈性計算爲雲上客戶提供了ECS GPU DeepGPU增強工具包,幫助用戶在雲上高效地構建AI訓練和AI推理基礎設施,從而提高算力利用效率。
目前,阿裏雲ECS DeepGPU已經幫助衆多客戶實現性能的大幅提升。其中,LLM微調訓練場景下性能最高可提升80%,Stable Difussion推理場景下性能最高可提升60%。
以下爲李鵬的演講實錄:
今天我分享的是關于AI基礎設施的演進和挑戰。我講的內容分三個部分:第一部分是關于生成式AI對雲基礎設施的挑戰;第二部分是如何進一步壓榨雲上GPU資源的性能,保證訓練和推理的效率達到最大化;第三部分是生成式AI場景下訓練和推理的客戶案例和最佳實踐。
一、算力需求規模10倍遞增,帶來三大計算結構挑戰關于生成式AI最近的發展和行業趨勢,我們看到的情況是,2023年生成式AI爆發,文生視頻、文生圖、文生文等場景下有很多垂類大模型或通用大模型出來。我和公司的産品團隊、架構師團隊與客戶進行了很多技術分享和交流。
我的感受是,現在很多雲上客戶逐漸在擁抱生成式AI場景,開始使用大模型,比較典型的行業是電子商務、影視、內容咨詢、辦公軟件這幾大部分。
大模型發展對AI算力的需求方面,左邊這張圖是前幾天GTC大會上黃仁勳展示的關于模型發展對算力的需求曲線圖。2018年開始,從Transformer模型到現在的GPT-MoE-1.8T,其對算力的需求呈現出10倍逐漸遞增的規模性增長,可以看出訓練的需求非常大。

另外,我們也做了一些估算,比如訓練1750億參數的GPT-3模型,訓練的計算量大概在3640PFLOP * 天,相當于需要大概1024張A100跑1個月,達到了千卡規模。換算到成本上就是一筆巨大的計算開銷。總體來看,因爲當前的GPU算力價格還比較昂貴,所以推理或微調本身的成本,以及計算需求和推理部署成本也會比較高。
大模型發展給計算體系結構帶來挑戰。
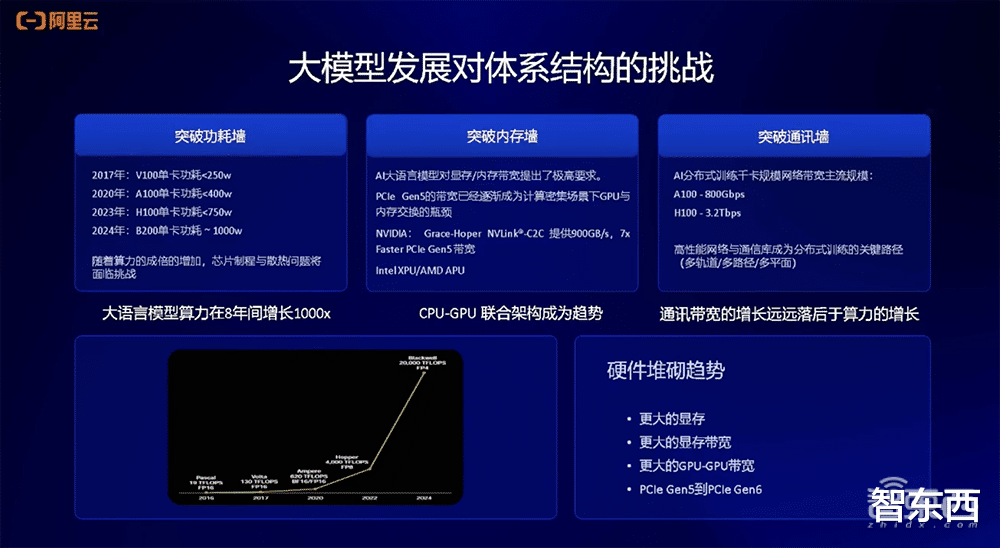
首先就是功耗牆的問題。以NVIDIA的GPU舉例,V100的功耗大概只有250W,A100功耗增加到400W,H100功耗達到750W,最新的B200功耗大概爲1000W。可以看到,算力8年間增長1000倍,其計算功耗也會相應增加。最近有相關的討論提到,AI的盡頭是能源,計算需求的增大會帶來更大的能源需求。
第二個體系結構挑戰就是內存牆。所謂內存牆,就是數據在CPU和GPU之間做搬移或者交換,現在PCIe的體系結構已經成爲數據交換和傳輸的瓶頸。目前,NVIDIA已經在Grace Hoper架構上推出了NVLink-C2C的方案,能夠大幅提升整個數據傳輸的速率。
第三個是通訊牆。分布式訓練的規模非常大,已經從去年的千卡規模達到了現在的萬卡甚至十萬卡的規模。分布式訓練場景下如何增強機器之間的互連帶寬有很大的挑戰。從國內外廠商的進展來看,他們會在A100上采用800Gbps互連的帶寬,在H100上采用3.2Tbps帶寬。
總結下來,現在的趨勢就是硬件堆砌,會有更大的顯存、更高的顯存帶寬、更高的CPU和GPU之間的互連帶寬,同時PCIe本身也會向下叠代。
以NVIDIA的GPU爲例,可以看到從Ampere這一代架構到Blackwell架構的變化。算力計算規模會越來越高,從不到1P增長到1P以上;顯存規格越來越高,從80GB增加到100多GB規模;顯存帶寬不斷增加。這反映了未來AI計算上硬件規格的變化趨勢。
二、大模型訓練的現實難題:模型裝載、並行、互連第二部分是大模型訓練對于雲上技術的挑戰。
大模型訓練技術棧包含Transformer模型結構、海量數據級、梯度尋優算法,這三塊構成了AI訓練的軟件和算法。硬件就是GPU計算卡,從單卡擴展到單機8卡的服務器,再擴展到千卡、萬卡互連規模的更大服務器集群,構成整個大模型訓練硬件的計算資源。
大模型訓練中遇到的典型現實問題是模型的加載和模型的並行。
以175B參數的GPT-3模型爲例,其訓練需要的顯存規模大概爲2800GB。我們可以根據A100 80GB來計算所需卡的數量。但是要解決的問題,一是我們需要多少張卡裝載模型?二是裝載這個模型之後如何提升訓練效率?解決這個問題就需要用到模型並行技術,現在已經有各種各樣的模型並行技術去解決這樣的問題。三是互連的問題,有NVLink單機內部互連、機器跟機器之間的互連網絡。對于分布式訓練來說,這都是非常重要的問題,因爲會在通信上産生瓶頸。
大模型訓練中的模型裝載過程中,175B模型以FP16精度計算,大概需要350GB顯存規模,模型梯度也需要350GB,優化器需要的顯存規模大概爲2100GB,合並起來大概是2800GB規模。分布式訓練框架目前已經有比較成熟的方案,比如NVIDIA的Megatron-LM框架、微軟開發DeepSpeed ZeRO3的算法,都可以用來解決模型裝載和並行的問題。
在大模型訓練方式上也有比較多的並行技術,包括張量並行、流水線並行、數據並行等。
在模型分布式訓練過程中,我們還看到一些比較關鍵的問題,如集合通信性能問題。比如在TP切分中會産生一些All-Reduce(全局歸約操作),這些操作夾雜在計算流當中,會産生計算中斷影響計算效率,因此會有相應的集合通信算法、優化軟件被開發出來,去解決集合通信性能的問題。
三、顯存、帶寬、量化,成大模型推理瓶頸大模型推理時我們需要關注三個點:一是顯存,模型參數量大小決定了需要多少顯存;二是帶寬,大模型推理時是訪存密集型計算方式,在計算當中需要頻繁訪問顯存,所以這種情況下帶寬的規格會影響推理速度;三是量化,現在很多模型發布時除了提供基礎的FP16精度的模型,還會提供量化後的模型,因爲低精度量化可以省下更多顯存,也可以提高帶寬訪問速度,這也是模型推理中業界經常會采用的一種技術。
總結下來就是,大模型推理有顯存瓶頸;在推理方面可以走多卡推理,訓練卡也可以用在推理業務,而且會産生不錯的效果。
我們在做模型微觀性能分析時發現,典型的Transformer-Decoder,很多大模型都是Decoder Only結構,裏面包含注意力結構和MLP層。

在這些算子中,我們通過微觀性能分析會看到,大部分的計算都是矩陣乘操作,實際85%的耗時都是訪存,進行顯存讀取。
由于大模型推理是自回歸的生成方式,上一個生成出來的Token會被用于下一個Token的計算。這種訪存方式就是我剛剛提到的訪存密集型計算。基于這種行爲,我們會把這些注意力結構和MLP層分別進行融合,形成更大的算子後執行推理,就會顯著提高計算的效率。
在大模型推理的帶寬需求方面,下圖展示了Llama 7B在A10、A100上推理性能的對比。在不同的Batch Size下,A100和AI的比例關系基本是一條比較水平的線(圖中紅線)。

這也可以反映A100的顯存帶寬和A10的顯存帶寬之間的比例關系,從側面印證了大模型推理基本是訪存密集型的操作,它的上限由GPU的HBM顯存帶寬決定。
除此之外,我們還分析了大模型推理時的通信性能。這裏主要說的通信性能是指單機內部的多卡推理,因爲如果跑Llama 70B的模型,僅靠A10一張卡沒辦法裝載,至少需要8張卡的規格進行裝載。
因爲計算時做了TP切分,實際計算是每張卡算一部分,算完之後進行All-Reduce通信操作,所以我們針對這種通信開銷做了性能分析。最明顯的是在推理卡A10上,通信開銷占比較高,達到端到端性能開銷的31%。
我們如何優化通信性能的開銷?通常來說比較直觀的方法是,如果有卡和卡之間的NVLink互連,性能自然會得到提升,因爲NVLink互連帶寬本身就比較高;另一個方法是,如果卡上沒有NVLink,你就需要一些PCIe的P2P通信,這也能幫助提高通信開銷占比。
基于在阿裏雲上的親和性分配調優,我們摸索出了一套調優方法,能夠在4卡、8卡場景下進一步優化通信開銷占比。
對于視頻模型,今年年初OpenAI發布Sora,雖然沒有公開太多技術細節,但國外機構已經給出了其關于算力需求的分析。
因爲Sora的模型結構與文生圖模型結構不同,其中比較顯著的區別就是,從原來的UNet結構變成Diffusion Transformer結構,通過結構上的變化和算力的估算,我們看到的結果就是Sora在訓練和推理上都會對算力有比較大的要求。
下圖是國外研究機構估計的算力需求,他們估算訓練Sora這樣的模型,需要大概4000到10000多張A100訓練1個月。在推理需求上,如果要像Sora這樣生成5分鍾長視頻,大概需要1張H100算1個小時。

阿裏雲彈性計算爲雲上客戶在AI場景提供了關于基礎産品的增強工具包DeepGPU。DeepGPU是阿裏雲針對生成式AI場景爲用戶提供的軟件工具和性能優化加速方案。用戶在雲上構建訓練或者推理的AI基礎設施時,該産品就能提高其使用GPU訓練和推理的效率。

這非常重要,因爲AI算力現階段比較貴,我們需要通過工具包的方式幫助用戶優化使用GPU的效率。我們也會提供文生圖、文生文等的解決方案,並且幫助衆多雲上客戶實現了性能的大幅提升。
接下來是阿裏雲幫助客戶進行訓練微調和推理案例。
第一個案例是文生圖場景下的微調訓練。我們將DPU和阿裏雲GPU結合,在客戶的業務場景下幫助客戶提升端到端微調的性能,大概會實現15%-40%提升。
第二個案例是關于大語言模型場景的微調。很多客戶想做垂直領域或者垂直場景下的大模型,會有模型微調的需求。針對這種需求,我們會做相應的定制性解決方案或優化方案,在這個場景下,客戶可以通過軟硬結合的優化方法,提升大概10%-80%的性能。
第三個案例是關于大語言模型的推理,這個客戶需要在細分場景做智能業務問答、咨詢等,我們在這個場景下爲客戶提供了端到端的場景優化方案,從容器、環境、AI套件、DeepGPU到下層雲服務器,幫助客戶優化端到端推理性能,這會幫助客戶提升接近5倍的端到端請求處理或推理的效率。
以上是李鵬演講內容的完整整理。
