文/VR陀螺
騰訊ARC Lab又有新動作,這一次,生成式AI的焦點放在了3D生成上。
不久前,騰訊ARC Lab發布了一種新的AI模型“InstantMesh”,可以使用單張靜態照片渲染3D對象。

圖源:InstantMesh
根據騰訊研究院的說法,InstantMesh是一種用于從單個圖像即時生成 3D 網格的前饋框架,能夠在10秒內創建多樣化的 3D 資産。通過網絡圖片實時轉換,InstantMesh可以生成元宇宙中的OBJ格式3D模型。
實際體驗下來,InstantMesh生成的模型質量見仁見智,但生成速度的確出乎意料。有用戶在社交媒體上展示了利用InstantMesh預置圖像生成3D模型的過程,並一連用“Super fast”“high quality”形容InstantMesh的輸出效果。
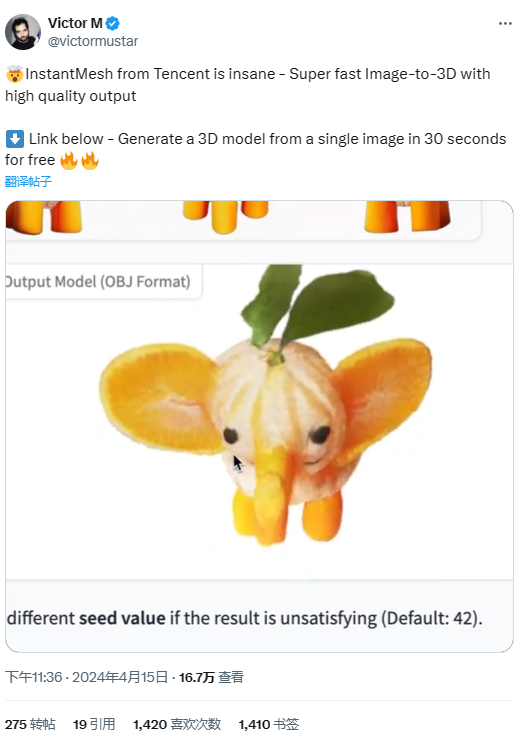
圖源:X
免去漫長的等待時間後,3D生成的效率這次真的提升了。
10秒內快速3D建模,還附贈模型六視圖InstantMesh的架構與Instant3D類似,都是由多視圖擴散模型和稀疏視圖重建模型組成。整個3D生成過程拆分爲了兩步:
首先,在給定輸入圖像後,使用多視圖擴散模型生成 3D 一致的多視圖圖像;然後,利用稀疏視圖大型重建模型直接預測3D網格,通過集成等值面提取模塊(即 FlexiCubes)渲染 3D 幾何形狀,並將深度和法線等幾何監督直接應用于網格表示以增強結果。幾秒鍾內就可以完成建模。

圖源:InstantMesh
1、多視圖擴散模型
面對單一輸入圖像,InstantMesh選擇了將具有可靠的多視圖一致性和定制的視點分布的Zero123++集成到框架之中,通過多視圖擴散模型生成圍繞對象調整的六個新視圖,捕捉全方位視角。同時微調Zero123++來合成一致的白色背景圖像,確保後期稀疏視圖重建過程的穩定性。
2、大型稀疏視圖重建模型
InstantMesh稀疏視圖重建模型架構在Instant3D的基礎上進行了修改和增強,訓練數據集由Objaverse 80萬個對象初始池中篩選出的大約 27 萬個高質量實例組成。
在訓練過程中,InstantMesh爲了與 Zero123++ 的輸出分辨率保持一致,將所有輸入圖像的大小都調整爲 320×320,並將 Zero123++ 生成的 6 張圖像作爲重建模型的輸入,以減輕多視圖不一致問題。
最後,生成的多視圖圖像進入基于Transformer的大型稀疏視圖重建模型,進行精細化的3D網格重建。

圖源:InstantMesh
而爲了進一步提升3D模型的質量與逼真度,InstantMesh還引入了等值面提取模塊FlexiCubes,可以直接作用于網格表示,將深度和法線等關鍵幾何信息融入重建過程,猶如爲3D模型披上了一件質地細膩、紋理豐富的外衣。得益于此,InstantMesh生成的模型在視覺上更爲細膩,在幾何結構上更爲精准,從內到外優化全面。
整個圖像到3D的轉化過程在短短10秒內即可完成,這無疑爲創作者開啓了全新的效率時代。

圖源:InstantMesh
無論是專業設計師尋求快速叠代設計方案,還是普通用戶渴望將生活瞬間轉化爲立體記憶,InstantMesh都能快速滿足需求。更重要的是,其強大的泛化能力確保了在面對各類開放域圖像時,都能生成合理且連貫的3D形狀,打破了傳統方法對特定數據集的依賴,實現了萬物皆可3D的跨越。
騰訊開發團隊聲稱實驗結果表明InstantMesh的性能顯著優于其他最新的圖像轉 3D 方法,那麽,站在使用者的角度,InstantMesh的輸出效果相比其他同類型的模型,是否真的做到了又快又好呢?
新的家具建模神器InstantMesh的生成速度有多快呢,實測從照片導入到最終的模型生成總用時不超過50秒,建模過程則基本維持在10秒左右。
對于模型質量,InstantMesh聲稱其生成的 3D 網格呈現出更加合理的幾何形狀和外觀。
實際使用下來發現,InstantMesh生成的模型具有完成清晰的表面,並且結構完整,這一點在生成家具等物體時尤爲明顯。
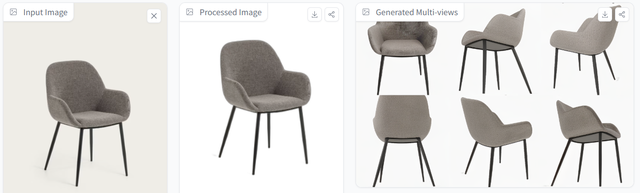

可以看到,生成的六視圖以及最終模型不僅完美複現了圖片視角的椅子材質結構形態,甚至連圖片中不可見的椅面連接處結構也複現得合理且准確。
而當圖片中出現兩個以上物體時,InstantMesh不僅能複現椅子和桌子的不同形態,甚至連二者的位置關系也完全一致。
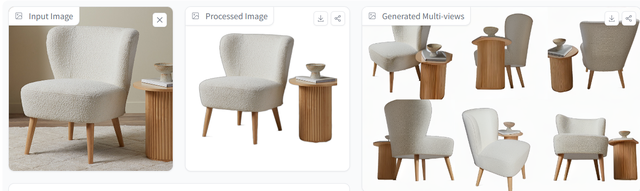

同樣的,在生成手辦、玩偶等虛擬形象的3D模型時,InstantMesh的表現也十分出色。
生成的3D模型幾乎已經可以看做是圖片內容的一比一手辦了,無論是在色彩、結構還是體積感上都處理得已經接近商用水准。只不過還是有瑕疵存在,在識別玩偶圖像中衣領部分時,模型似乎不知道如何呈現衣領部分,而是簡單的將其去除,導致玩偶3D模型看起來脖子過長。




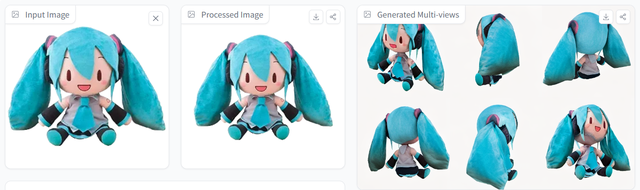

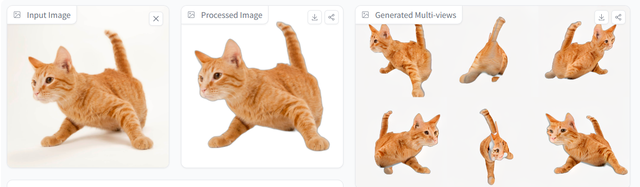
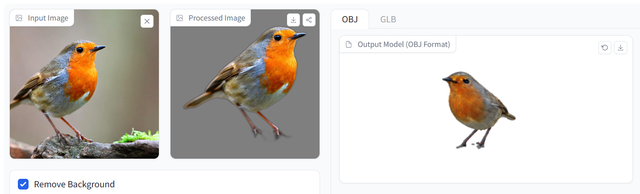
而在處理動物等現實生物的圖像時,InstantMesh就開始顯得力不從心了。
可以看到,在處理幾何形狀簡單的動物形象(比如下圖的鳥)時,InstantMesh水平仍舊在線,對于圖片整體十分還原,唯一的不足出現在摳圖上,導致模型腿部缺失,爲3D建模拖了後腿。


而面對更加複雜的動物圖像,InstantMesh雖然盡力還原除了模型的大概,但也出現了臉部細節缺失、背部材質缺失等不足。


甚至,在面對連人類都會疑惑的“奇怪動物”時,InstantMesh同樣也無從下手,當然,這一點無法苛責InstantMesh,畢竟目前的AI還無法向人類這樣理解世界,至少在圖片視角上,InstantMesh已經做到了還原,也算是合格了。

在論文中,InstantMesh不僅展示了自身的能力,還與TripoSR、LGM等類似的生成模型作了效果對比,稱“TripoSR結果令人滿意但缺乏想象力”“LGM等具有想象力但明顯多視圖不一致”。
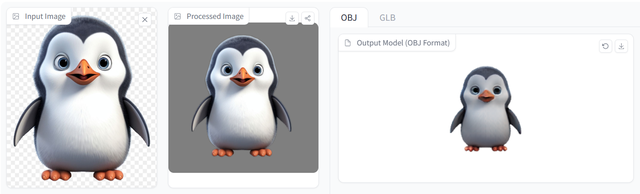
那麽,在同樣的輸入下,TripoSR和LGM的實際表現如何?
可以看到,TripoSR生成模型的質量在細節把控上優于InstantMesh,但相比之下,TripoSR對于體積感的把握並沒有能夠勝過InstantMesh,生成的企鵝形象未能像圖片展示的一樣飽滿,從側面看仿佛被砍了一刀。


而LGM生成的模型完美呈現了圖片中沒有展示的部分,且模型材質、形態控制出色,不足之處在于模型出現了輕微的重影,且在尾巴、後腿部分出現了不必要的模型粘連增生。


可以說,至少在生成模型的結果以及模型的可用程度上,InstantMesh已經達到了TripoSR的水准,並略優于LGM,並且由于生成的時間被壓縮至10秒左右,大大加速了建模效率。
但同時,受制于輸出過程中的分辨率控制,InstantMesh輸出的圖像在清晰度上明顯遇到了瓶頸,雖然研發團隊有意在未來的工作中解決這一限制,但即使解決了清晰度問題,由于客觀存在的多視圖不一致、細節建模問題,InstantMesh的建模效果離商用也還存在著一定差距。
至少目前來看,InstantMesh的應用場景更多可能還是在遊戲3D資産等對建模精細度要求不高的領域上。當然,作爲新一代的家具建模神器,在電商領域未來或許也能有InstantMesh的一席之地。
在蘋果Vision Pro推出後,電商平台百思買 (Best Buy)、淘寶等都宣布了相關原生應用上線計劃。

圖源:百思買
從百思買已經公布的電商購物應用《Best Buy Envision》來看,用戶在購買之前就可以在Vision Pro界面中浏覽産品的3D模型外觀,這意味著一款擁有數以萬計商品的購物軟件的背後有著同樣數量級的3D資産需求,而電商産品的叠代速度之快又要求企業能以速度更快、成本更低的方式完成商品建模,這使得以InstantMesh爲代表的AI建模未來有機會成爲電商人的標配工具。
3D生成的終點不是場景建模InstantMesh還在努力,但現在的3D生成技術已經不滿足于純粹的場景物體建模了,時下熱門的數字人行業是更大的市場。

韓國數字人女團(圖源:PULSE9)
3D生成技術在數字人領域的應用前景更多體現在超寫實3D數字人建模上。
根據上海交通大學人工智能研究所的一篇論文顯示,AI主要通過數據驅動的方式學習真實的數據分布、對數據分布進行采樣以生成新的樣本表示,並對數據表示進行渲染從而打造出高度真實的三維數字人。
而在3D數字人模型的表示方式上,常見的表示方式可以分爲顯式表示和隱式表示兩種形式。其中, 顯式表示一般直接給出滿足條件的所有元素的集合,如點雲包含三維空間中點的位置,多邊形網格則包含頂點位置及其連接關系等信息。

圖源:上海交通大學智能研究所
這一方法通常被應用在遊戲、影視制作等工業應用中,優點在于傳統的渲染管線已經能對其進行高效處理,但缺點在于生成模型的精細程度會受到分辨率限制,在對數字人高擬真外表的要求下,模型細節的增加會造成模型複雜度的上升。
在分辨率的硬性要求下,隱式表示就要好用得多。僅僅需要符號距離函數、水平集等三維空間約束,隱式表示就能夠使數字人模型突破空間分辨率的限制,此外,使用深度符號距離函數、神經輻射場等神經網絡逼近隱式函數還能恢複出數字人的精細幾何與紋理,相比顯式表示更加靈活。
國內團隊推出的文本指導的漸進式3D生成框架DreamFace就結合了視覺-語言模型、隱式擴散模型和基于物理的材質擴散技術,可以生成符合計算機圖形制作標准的3D數字人形象。
DreamFace不僅支持基于文本提示的發型和顔色生成,生成的模型還具備動畫能力,能夠提供更細致的表情細節,並且能夠精細地捕捉表演。

圖源:DreamFace
而在國外,更有以谷歌DreamHuman爲代表的的文字生成帶動畫3D數字角色技術。
DreamHuman將大型文本到圖像合成模型、神經輻射場和統計人體模型連接到新的建模和優化框架中,使得生成具有高質量紋理和特定要求的動態3D人體模型成爲可能。

圖源:DreamHuman
經過完整的生成式三維數字人建模流程之後, 生成模型將學習到數字人的先驗信息, 針對模型進行相應微調即可應用到下遊任務。
特別是在數字人重建應用中,生成式數字人模型爲重建任務提供了有效的先驗約束,不僅有助于生成合理的重建結果,也減少了對于訓練標簽的要求,降低了重建成本。只需要從圖像或視頻中恢複人體和人臉的三維幾何形狀以及對應的外觀信息, 就可以實現真人與虛擬數字人一對一的數字化映射。

微軟VASA-1(圖源:微軟)
代表應用既有從單張圖片重建出目標人3D化身,並合成支持大姿態驅動的真實說話人視頻的“單圖 3D 說話人視頻合成技術 (One-shot 3D Talking Face Generation) ”,也有無需複雜采樣和建模,只要一段幾秒鍾視頻就能實現人物動作流暢的3D數字人合成工具“HUGS”(Human Gaussian Splats)。
其中,HUGS由蘋果推出,是一種基于高斯函數的生成式AI技術,可以通過3D Gaussian Splatting(3DGS)和SMPL身體模型的融合創造出更加生動和真實的數字人物。

圖源:HUGS
蘋果對于數字人的研究並非一時興起,而是有實際服務于産品的先例。在VisionPro上,用戶就可以通過前置攝像頭掃描面部信息,並基于機器學習技術和編碼神經網絡生成數字分身。當用戶使用FaceTime通話時,數字分身還可以模仿用戶的面部表情及手部動作。
可以預見,HUGS等技術的加入將使數字人形象無論是在二維平面屏幕還是三維元宇宙空間中都能演繹出生動逼真的表演。在AI的加持下,無論是智能助手、虛擬現實遊戲,還是視頻會議等多元場景,未來都將被“身手矯健”的虛擬人占據,爲用戶帶來與現實無異的沉浸式互動體驗。
而這也是InstantMesh們未來可以選擇的方向。

圖源:蘋果
從遊戲場景物體到虛擬人、虛擬世界,AI正在以複制現實世界爲目標進步,在相關技術進一步完善與融合後,只需要一段文字、一張圖片、一段視頻,就可以構建一個場景真實、人物逼真的幻象空間。
我們有理由期待AI生成技術將以更快的步伐不斷叠代,帶來愈發驚豔的視覺享受與生活便利。虛擬現實的好日子還在後頭。
