
作者 | GenAICon 2024
智東西5月6日報道,2024中國生成式AI大會于4月18-19日在北京舉行,在大會首日的主會場開幕式上,阿裏巴巴通義實驗室XR團隊負責人薄列峰博士以《人物視頻生成新範式》爲題發表演講。
隨著Sora等文生視頻模型掀起熱潮,很多人都在探討文生視頻模型能不能算作世界模型。對此,薄列峰認爲,文生視頻模型與世界模型的機制存在差異,視頻是一個觀察者角色,並不能真正改變世界,文字與物理世界描述之間也具有不對應關系。
人物視頻生成模型是阿裏通義實驗室XR團隊的一個研究重點。薄列峰通過人物動作、人物換裝、人物替身、人物唱演4個框架來解讀人物視頻生成新範式。基于這些框架的應用,正逐步落地通義千問APP。
人物動作視頻生成框架Animate Anyone可基于單張圖和動作序列,輸出穩定、可控的人物動作視頻;人物換裝視頻生成框架Outfit Anyone是基于服飾圖和人物形象;人物視頻角色替換框架Motionshop采用Video2Motion,基于視頻人物動作驅動3D數字人;人物唱演視頻生成框架Emote Portrait Alive能夠基于單張圖和音頻,輸出准確、生動的人物唱演視頻。
以下爲薄列峰的演講實錄:
我的分享前半部分講行業趨勢以及我在多模態、文生文等方向的思考;後半部分分享我們在文生視頻生成方向的工作。可以非常自信地說,我們在整個業界具備領先性,整個工作也有很強的特色。
一、文生視頻模型基于統計關系,不是世界模型首先,文生視頻高速發展,大家講發展基石的時候都會講到數據、機器、人才。什麽是多模態?什麽是視頻?文生視頻這個領域基礎又是什麽?目前思考得還比較少。
先回顧一下進程,大家可以看到Midjourney在文生圖方向的突破;OpenAI借助非常強的理解大模型、能夠對圖像實現精標的能力,在文生圖上做出自己有特色的工作和突破;創業公司像Pika、Runway也在做自己的工作,分別從不同的路徑和方向來演進;包括谷歌、大的創業公司,過去一年有很多文生視頻方向的研究工作。
這些工作從研究的角度有一定數量的數據集,做一些方向的突破可能沒有那麽難。OpenAI相當于把這個事情做到了極致,在現在的時間節點,整個Sora展示出非常好的效果。
文生視頻是不是世界模型?它和世界模型的機制還是有所差異的。
首先視頻是一個觀察者的角色,我們有一些攝像機在記錄這個世界,但它不是真的去改變這個世界。如果說我需要做一些世界模型,類似我需要一些具身智能,當然這也是大家提出的一些新名詞,具身智能是在仿照我們生物智能。生物智能不光有思考,同樣也有實體,如果看實體的部分,具身智能現階段還是遠遠落後的,因爲人體具備非常強的靈活性和低碳的消耗,不是今天物理機器所具備的,這是一個差異點。
另一點,如果看文生視頻,視頻的存在並不依賴于文字是否存在。文字出現以前,地球上的生物就可以看到這個物理世界。文字是我們引入去描述人自身的思想,隨著人類進化了很多代,是我們引入的一個工具,實際可能跟今天的編程語言也是類似的。我們引入一個工具來描述這個物理世界,它具有相當的描述能力,但是它和物理世界之間也不對應,也就是說它有簡化、有抽象、有歸納等。
整個文生視頻做的工作是什麽?有一個視頻空間,還有一個文字空間。我們在文字空間給每個視頻打上標或者找到一個對應。整個關系是一個統計的依賴關系,通過這樣的關系和暴力的關聯,再加上大數據,展現出了一定的文生視頻能力,但是不代表這是我們物理世界真實運作的規律。
如果看文生文、文生視頻,它們並不影響我們的物理世界,如果要影響物理世界,它還是需要達到生物智能所具備的特點。
在這裏也分享我對AGI的理解。通過文字我們是否能實現AGI?首先文字的能力于生物智能而言,不是完整的。非完整的AI智能是否達到人類智能所具備的能力?現在看還是有相當的距離。如果今天讓大模型去造一輛汽車,造一台電視可以嗎?以我的觀點來看,還是比較遙遠的。
二、做特色的人物視頻生成,能換裝唱演、角色富有表現力通義實驗室在視頻生成方向有一些探索,我們也有完整的視頻生成矩陣性的産品和研究。
回到今天分享主題的核心——人物視頻生成,當大家討論這個問題的時候,第一個問題是,爲什麽不做一個通用的視頻生成就完了,爲什麽還要做人物視頻生成?
視頻生成和人物視頻生成有共性,需要高質量的畫質,包括整個運動要符合物理規律。如果看人的組成,包括人臉、人手、人的頭發、人的服飾都具有相當的唯一性,同時展示出了非常精細的顆粒度。人物的特點、聲音,這些還是人的感知部分,我們都還沒有講到人的實體部分,包括人是由物質組成的等,不同的部分是不同的物質,這些模擬可能是另一個層面,包括我們是否能制造出一種材料跟生物智能是類似的等等,這部分不是我們覆蓋的主題。
整體來看,它(人物視頻生成)是相當有特色的,會導致在生成中有很多特性,包括控制是多樣的,比如可以用聲音來做控制,可以用人體的一些表達來做控制,可以用文本來做控制。控制具備豐富性,同時它生成的人的整體表現力需要非常豐富,如果生成的人表現力非常呆板,很難滿足今天應用的需求。另外,生成的顆粒度、數字資産和人物運動的分離等,都是極具特色的部分。
我們的工作包括人物動作、人物換裝、人物替身、人物唱演等。接下來分享每個模塊各自的工作。
三、人物動作視頻生成框架Animate Anyone:讓兵馬俑跳《科目三》第一部分,我們在2023年11月發布人物動作視頻生成框架Animate Anyone,在人物視頻生成方向的發布早于Sora幾個月,當我們把這個結果發布出來之後,引發了非常強烈的關注,主要是達到的視覺效果超越了之前的結果,可以說是一個數量級的超越。

整個方案的框架有幾個特色:
第一,有一張參考圖,整個生成過程會對參考圖做高度的保真。大家如果在生成的時候看視頻的細節,可能會發現,隨著時間的推移,整個像素的物理合理性可能不太對。我們有機制,在融入的過程中,不光有CLIP的特征,還有視覺特征的融入,可以把更精確的信息編碼進來,這是一個特點。
第二個特點,我們用骨骼訓練控制人物的動作。大家如果看整個人體的模擬,特別是整個人體的關節,每個關節點有它的自由度,整體上骨骼與人體也是非常匹配的表達。
第三,引入時序模塊,保證時序上的一致性。我們和Sora的效果對比,視頻效果比Sora的方法有一個非常明顯的提升。
我們也把技術産品化,部署到通義APP,歡迎大家下載體驗。
我們的舞蹈生成獲得了相當多的關注,整個視頻內容播放達到了非常高的數字。畫面中的舞蹈,包括真人、卡通形象(都可以)來跳《科目三》。
當看産品演進的時候,我們發現一個非常有意思的事情,真人來跳舞這件事是我們自己可以去實現的能力,雖然對于每個人而言難度各有不同,舞蹈跳得比較好的能跳出比較好的《科目三》,舞蹈跳得不好也能跳出《科目三》的樣子。但是對于一些其它類人的形象,比如兵馬俑,我們不太可能去讓它跳《科目三》。
如果過去要讓一個兵馬俑跳《科目三》,我們要走的流程是什麽?(以前)我們要做一個三維模型,人爲設計它的動作,整個成本流程非常高。我們現在只要輸入一張照片,兵馬俑就可以跳《科目三》。畫一幅畫,給自己喜歡的寵物拍一張照片,輸入喜歡的各種二次元形象,它都可以來跳創作者喜歡的舞蹈。
Animate Anyone賦予創作者相當大的靈活度,特別在之前很難創作出這樣動作視頻的領域,給大家提供了一個工具。
新的功能也在開發中,包括任意上傳一段視頻可以來提取骨骼序列,然後把骨骼序列傳遞的動作信息轉移到這張照片上面,生成一段舞蹈。這會再次釋放大家動作視頻創作方面的潛力,甚至一些有難度的類人形象,我們能夠通過手繪骨骼點,讓它也跳起來舞蹈。我們把手繪的骨骼點和自身定義的骨骼點做一個匹配,來完成這樣一個工作。
Animate Anyone發布的時候,四個視頻在(社交平台)Twitter上總播放量破億,還有大量的自發報道。
四、人物換裝視頻生成框架Outfit Anyone:一鍵爲模特換裝第二部分,人物換裝視頻生成框架Outfit Anyone。在一個文明社會,每個人都有穿著服飾的需求,對美觀度有極高的需求。我們打造了一個框架,可以給定一個服飾,然後讓這個服飾穿到自己或者模特的身上,具備細節可控、身材可調、全身穿搭甚至多層服飾的疊穿等特征,面臨非常細節問題的處理。
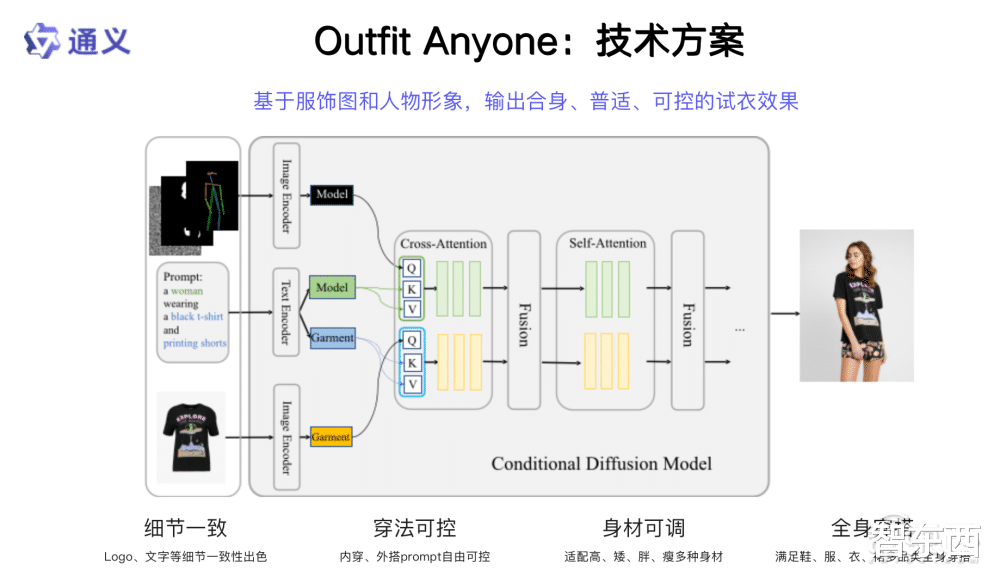
當我們真正要滿足大家需求的時候,服飾的一致性非常重要,疊穿怎麽和拍得高質量照片達到一樣的畫質、精度,相當有挑戰。
在一個模特換裝應用中,將鼠標點擊、上移、下移,點擊試穿,就會讓模特試穿衣服。我給定一些特別的材質,比如香蕉(圖像)等,我們也能把它當衣服一樣穿到身上來。整個模型在嘗試把各種各樣的布料或者類似布料的東西上身,爲創意提供了一個路徑。
當然我們也可以把Outfit Anyone和Animate Anyone結合,去生成一段走秀視頻等。相關作品獲得了相當的關注,在Hugging Face上榜,關注度非常高。
五、人物視頻角色替換框架Motionshop:生成3D模型動作視頻人物視頻角色替換框架Motionshop,給定一個視頻,提取它的骨骼,同時把骨骼和三維模型做綁定,生成三維模型的動作視頻,然後還原在原視頻中。這樣的視頻和Animate Anyone的區別是,3D資産(包括3D IP)也是相當大的領域,特別在遊戲和影視,現在的Motionshop方案支持多視角的方案。

Motionshop支持多人替換,這樣的視頻替換成二次元的角色,後面的視頻背景相當真實,前面的人物是虛擬人物,包括實際幹活兒的視頻。這裏也産生了一些對機器人能力的思考。
在整個方案中,要讓整個視頻看起來非常真實,除了大模型的能力,我們還運用了渲染的能力,包括光線追蹤,會從原視頻估計光照等,這樣讓整個視頻看起來非常一致,沒有違和感。
把機器人帶到對話場景中,也是非常有意思的一個應用。整個置換會在場景中有非常好的體現,超越了目前一些類似的方法所能做到的能力。
六、人物唱演視頻生成框架Emote Portrait Alive:讓照片開口唱歌年後我們沿著對人物視頻生成獨立的思考,不斷地向前探索,最新的工作是人物唱演視頻生成框架Emote Portrait Alive。給定一張照片,可以讓這個人來唱歌、講話(這項功能已于近期上線通義APP)。當然了,四五年前大家都在研發這樣的能力,對于人物視頻生成而言,表現力是極度重要的,如果今天達到一個類人的表現力,在我來看是很難實現的。
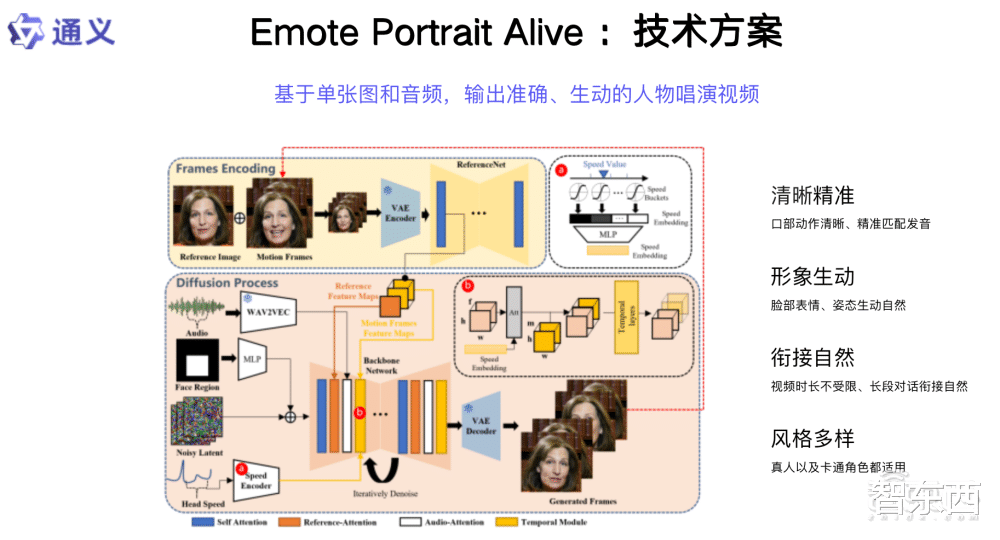
我們要達到專業級,這才是真正大家使用的內容生成。很多生成的視頻畫質是OK的,但是大家有沒有思考這樣的問題,比如說文生圖、生成的視頻,你是這個視頻的消費者嗎?你會看嗎?當然模型可能會生成這個世界上不存在的物種,這是很有意思的,但你會長期去消費這樣的內容嗎?
我覺得在做AIGC內容生成之前,不管是基礎研究還是應用思考,大家都在高速叠代,每個人都有自己的思考和對這個問題的答案。
在我們生成的過程中,基于這樣一個包括動作、唱歌(嘴型)、聲音表演的生成,我們可以去打造一個非常有吸引力的甚至可以去做演藝的形象,甚至可以做一個虛擬的明星。
以上是薄列峰演講內容的完整整理。
