導讀 大家好,我是來自九章雲極DataCanvas的王庚,我今天分享的題目是《保姆級拆解向量數據庫的結構和應用場景》。
主要內容包括以下幾個部分:
1. NewDataStack 時代的數據架構地圖
2. 向量數據庫發展曆程
3. 企業面臨痛點&挑戰
4. 向量數據庫整體形態
5. 向量數據功能特性
6. 多模態向量數據庫未來發展趨勢及核心能力
7. 向量數據庫重點支撐場景
8. 基于大模型的知識管家(Agent)向量數據庫應用
分享嘉賓|王庚 九章雲極DataCanvas
編輯整理|陳沃晨
內容校對|李瑤
出品社區|DataFun
01
NewDataStack 時代的數據架構地圖
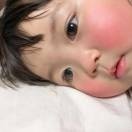
首先來看一張 Andreessen Horowitz 發布的關于未來數據架構的預測圖。我們在後面又加入了對應的當前比較流行的大模型以及向量數據庫。
首先最左側的是數據源層,這裏包括來自于企業各種各樣的數據源,我們也叫它多元異構的數據形態。有了這部分數據之後,首先要做的是數據的攝取,再往後是數據的轉化,這裏面涉及到非常多類型數據的形態轉換。包括傳統企業數倉的 ETL 過程,以及當前 AI 背景下的特征加工、數據處理等流程。還有處理流式數據、實時數據的數據組件,用來滿足高時效、低延遲的處理需求。
在數據存儲與計算層,向量數據庫一方面可以把前面各種各樣的數據做比較好的接入,還可以完成數據處理上的一些轉換,實際上在向量數據庫計算引擎的加持下,我們可以完成面向各種類型的數據存儲以及計算。
在數據分析與預測層,向量數據庫也可以提供比較全面的支撐,包括 AI 基礎小模型和大模型應用的場景,特別是在大模型方面,大家的共識是把向量數據庫作爲大模型應用非常重要的記憶體。除了上面說到的 AI 這部分場景,對一些傳統業務的支持,比如高效的即席查詢、實時數據分析以及向量的搜索、分析場景,向量數據庫都能發揮重要價值。
最後的數據應用層則對應一些具體的業務場景,比如 BI 儀表盤、嵌入式分析、增強分析、自助分析程序等。
02
向量數據庫發展曆程
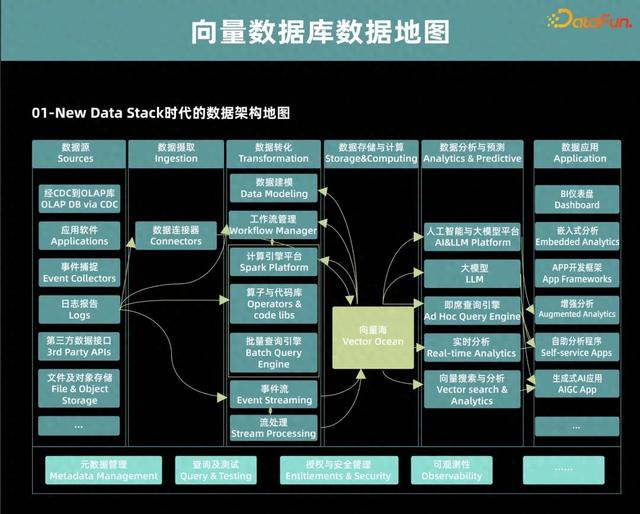
向量數據庫的發展大致經過了三個階段:
第一個階段是探索階段。主要以文件形式存儲向量數據,還沒有具備有效的索引以及查詢的能力,代表産品如 Lucene 等。第二個階段是發展階段。大家已經開始使用像 KD 樹等索引結構,可以實現一定查詢性能的提升,但是在高維空間的查詢效率還是遠遠不夠,代表産品如 Annoy、FAISS 等。第三個階段是應用階段。隨著大家對大模型認知的提升以及一些應用場景的擴展,又對向量數據庫的發展提了很多新要求,因此向量數據庫也具備了一些新的特性,比如高效的向量索引和查詢、處理海量的高維向量數據,這個階段也湧現出了大批比較優秀的向量數據庫,代表産品如ElasticSearch、DingoDB、Weaviate 等。03
企業面臨痛點&挑戰

在大模型時代,企業對于多模態數據會有越來越多的應用場景,在多模態數據的分析和檢索方面將會面臨很多挑戰以及問題。大概分爲以下四個方面:
第一個是如何有效地去應對大模型時代數據架構的變化。從底層數據的角度來看,向量是人工智能理解世界的一種通用的數據形式,特別是在大模型時代,整個基于 Transformer 架構的計算,以及對數據快速 Embedding 的轉化,其實都是基于向量去做的,大家常常把向量數據庫稱爲是大模型記憶的存儲核心,因此企業如何結合向量數據庫進行企業級大模型數據架構的規劃就變得非常重要。第二個是多模態數據聯合存儲、分析、服務難題。這裏面包含結構化與非結構化數據混合存儲的問題,以及在保障性能的前提下,實現向量數據、標量數據的混合檢索。爲了支撐豐富多樣的數據服務場景,要求我們的數據架構要能很好地應對多模態的數據在存儲、分析、服務等各個方面可能會面臨的問題。第三個是如何滿足高性能、易運維的企業級應用需求。海量的數據索引會帶來運維的難題,包括怎樣去優化當前的索引,以及把大批量的數據做初始化;向量數據庫在運行的過程中,對于不同業務場景的響應是否能滿足多並發低延遲的服務響應,如何降低運維的複雜度,減少企業的應用成本,這些都是企業要去實際考慮的問題。第四個是企業數據如何安全可靠應用。數據高可用會涉及到像 HAI 分布式環境下的數據管理、備份等問題。數據權限除了多租戶數據隔離,企業通常還要保障數據的安全和被高效地利用。當然,還有很重要的一點是當前形勢下對于國産化信創的要求。04
向量數據庫整體形態

前文提到向量數據庫的數據來源可能包括結構化數據與非結構化數據,所以從這張圖上可以看到像圖片、文檔、音頻以及視頻這些數據都要做向量化轉換才能存到向量數據庫。對于我們原來經常接觸的一些關系型數據庫數據,以及 Key-Value 這種半結構化數據,也要統一存儲。海量數據在向量數據庫做向量的轉換,用來提供相似性的檢索。再上層是向量數據庫通過其分析和計算引擎支撐 BI、流分析、AI、數據科學以及大模型等不同的場景。

上圖左側是數據的來源,有各種各樣多模態的數據類型。從上往下看,最上面是我們通過向量數據庫實現的一些場景,包括關系數據分析、語義數據檢索、實時決策、提示詞管理和大模型記憶的管理。下面展示了各種各樣的服務形態,包括兼容MySQL 協議、提供 Serving API 的對接、面向原生向量的 API。再往下是向量數據庫所要具備的元數據存儲與資源管理能力,以及一些優化的組件,比如多模優化器和事務管理器,用來保證向量數據庫高效地運行。最底層是數據存儲的形態,有關系型存儲、向量存儲以及 HDFS 倉存儲和湖存儲。
05
向量數據功能特性
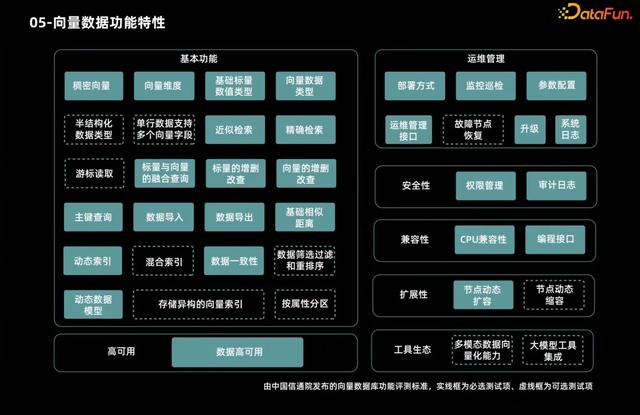
這是中國信通院組織 50 家企業的專家在一起討論了大概 3-4 個月形成的一個行業通用標准,它定義了向量數據庫的基本功能、運維管理、安全性、兼容性、擴展性、高可用等多個方面的標准,可以比較全面地看到向量數據庫的一些技術指標要求。
06
多模態向量數據庫未來發展趨勢及核心能力

多模態向量數據庫的未來發展趨勢及核心能力可以總結爲以下五個方面:
第一個是支持標量、向量數據的混合聯合查詢。既要同時支持傳統的數據庫索引的類型和比較豐富的向量索引的類型,又要能夠無縫銜接標量向量混合檢索體驗,還要有領先的檢索能力。第二個是具備多樣化的訪問接口。向量數據庫對外提供服務時,我們還是希望它有像 SQL、SDK、API 等多樣化的服務形態,在不同場景下提供合適的訪問方式。比如在時效性要求特別高的場景適合集成 SDK 或者高頻 Serving 的 API。在面向 Table 和 Vector 數據模型時,不管是用向量或者關系型,都可以做一些靈活的配置跟轉換。第三個是全自動的彈性數據分片。當我們把大批量的數據導入進來之後,向量數據庫可以自動對數據分片大小進行動態設置,並完成自動分裂與合並,爲用戶提供靈活的空間和資源配置策略。第四個是實時索引構建自優化。數據存儲之後,可以實時構建標量和向量的索引,並且具備用戶無感知的後台自動索引優化。而且索引不僅僅局限于某一種類型向量數據庫,在向量入庫的時候,我們就可以選擇一種索引去作爲數據組織的基本形態,提供無延遲的數據檢索能力支持。第五個是內建的數據高可用。我們希望向量數據庫無需部署任何外部組件,所有功能和高可用全部內置,這樣既能減少跟其他組件的適配成本,同時也可以極大降低企業的部署及運維成本。07
向量數據庫重點支撐場景

簡單來講,在大模型時代,多模向量數據庫的重點支撐場景包括大模型記憶體、企業知識庫、非結構化數據檢索、實時決策指標計算、結構化與非結構化數據的融合分析和 VectorOcean 數據支撐平台等。
08
基于大模型的知識管家(Agent)向量數據庫應用

向量數據庫作爲大模型知識管家後台的核心存儲引擎,一方面把各種類型的企業數據進行私有化的存儲,然後在這個基礎上用大模型去跟向量數據庫做高效的交互。另一方面是用戶在提問之後,可以通過大模型先對語言做基礎的組織,然後用向量數據庫查詢出最相似的知識片段 TopN,並把這些知識片段作爲基礎語料傳送給大模型,大模型去做答案的組織,再結合大模型的生成式的能力給出最終答案。通過這個過程可以大大降低大模型應用換輪的問題,能夠讓用戶得到更可靠的問答。
以上就是本次分享的內容,謝謝大家。