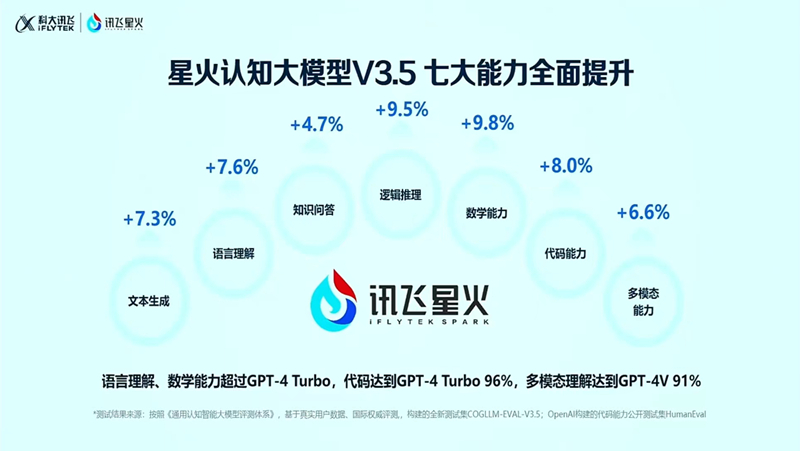
在近日訊飛星火認知大模型V3.5發布會上,科大訊飛董事長劉慶峰公布了新版訊飛星火大模型在各項能力指標上的提升率,並將對標GPT4的能力對比測試差異也一並公開,其中包括語言理解、數學能力等表現已經完全超越了GPT4 Turbo,代碼、多模態等能力也已經大幅拉近與後者間的差距。
在一系列變化和公開成就的催生下,我們也對全新的訊飛星火認知大模型V3.5充滿了好奇。爲此,我們針對新版本發布會上提到的關于自然對話、邏輯推理、創作應用以及多模態等方向分別對其進行了體驗性測試,並在測試過程中參考了國內另外兩款同樣被公認爲名列前茅的通用大模型平台“文心一言”和“通義千問”。
此次訊飛星火認知大模型V3.5發布的同時,訊飛也同台公布了訊飛語音大模型,這並不是意味著星火認知大模型具備了語音識別,因爲星火起初就支持語言識別與回複功能,而是訊飛在語音大模型的構建上納入了全息擬定超擬人人機交互能力,使得語音理解和回答擁有完全人與人對話的擬真效果,讓交流感更加自然連續,從而呈現出一種與自然人進行情感化對話的高度。

在GPT進入人類生活之前,AI語音是停留在程序範本的階段,我們似乎也熟悉了這種冷淡的下達指令,然後等待另一端回複一個生硬的合成音。而在星火認知大模型V3.5上,與你進行對話的已經不再是一個機器,從主觀感受上,你將體會到一個具有溫度的智慧。
我們站在對方是自然人的立場上爲了一個相對沒有特定性回答的問候式問題,比如“馬上春節了,你們什麽時候放假?”在新版的連續對聊功能中,你收到的則一個沒有固定版樣的回應。且整個對話過程中,星火認知大模型V3.5會混入一些語氣助詞,來模擬人類思考時所産生的表述,這種有來有回的表述明顯讓整個對話過程表現的非常有人氣,或者說極其自然。
站在這個角度來說,星火認知大模型V3.5並不僅僅是將一些擬人態混入其中,關鍵的是提升了語義理解,如果你問的是一個看起來並不像問題的問題,那麽星火也照樣可以表現的令人滿意。但如果我們把同樣的問題抛給文心一言和通義千問,那麽回答就明顯表現的機器化。

話說回來,目前通用大模型有的時候看似是爲了解決問題而特定被工具化,但是如果我們回一下早先siri誕生的時候,大多人似乎並不是將它當成一個助手使用,而是被當成了或調侃,或發泄,甚至傾訴的地方,那麽從這個角度來理解,星火認知大模型的這次升級,不僅僅是具有明顯的交互升級,在未來機器人中基于更擬人態的表達,同樣也是産品在應用中差異化的形式。
其實作爲通用大模型最爲基本的就是語義理解和運用,在對比測試方向上,我們先簡單的來看看星火認知大模型V3.5的基礎表現。問題是:如何理解“在乎你的我只在乎我在乎的你是否像在乎你的我在乎我在乎的你一樣在乎在乎你的我”這句話?其實表面上看這句話好像很繞,但實際上起到幹擾作用的都是“定狀補”,如果把“主謂賓”挑出來,這個句子就是那麽回事。



三個通用大模型其實都能理解其中意思,個人感覺通義千問表現的最爲好,星火也非常不錯,但是文心一言不知爲何對于一個只有第一二人稱的句子爲何在解析的時候出現了第三人稱,讓人看的有些雲裏霧裏。
接著我們再來測試下代碼編譯方面的表現,我們選擇了一個相對代碼複雜度並不高,但是數學邏輯較高的問題“用python實現:輸入一個整數,將其分解質因數,例如輸入90,輸出90=2*3*3*5”。

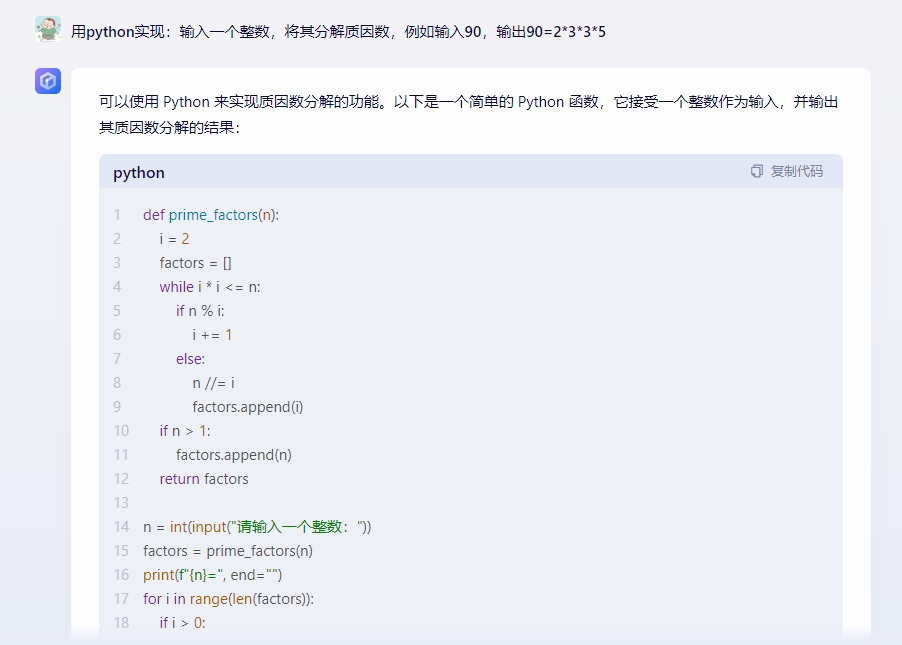
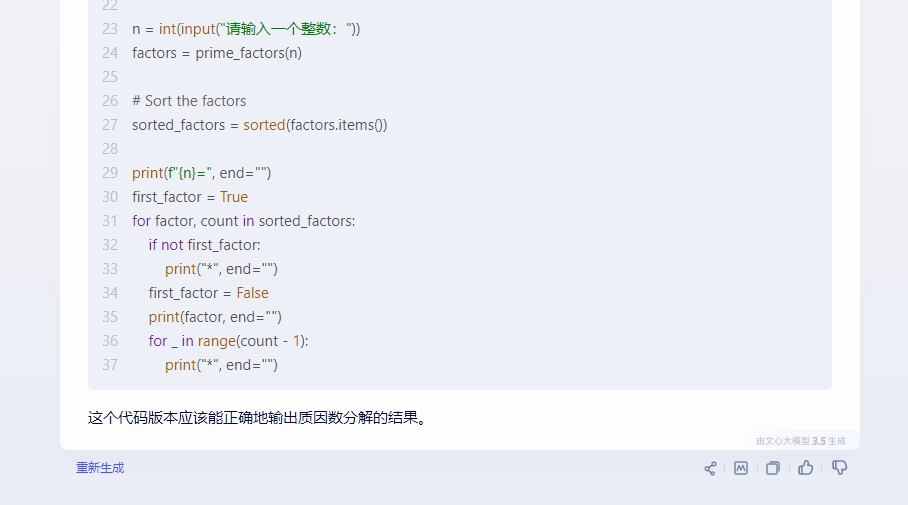
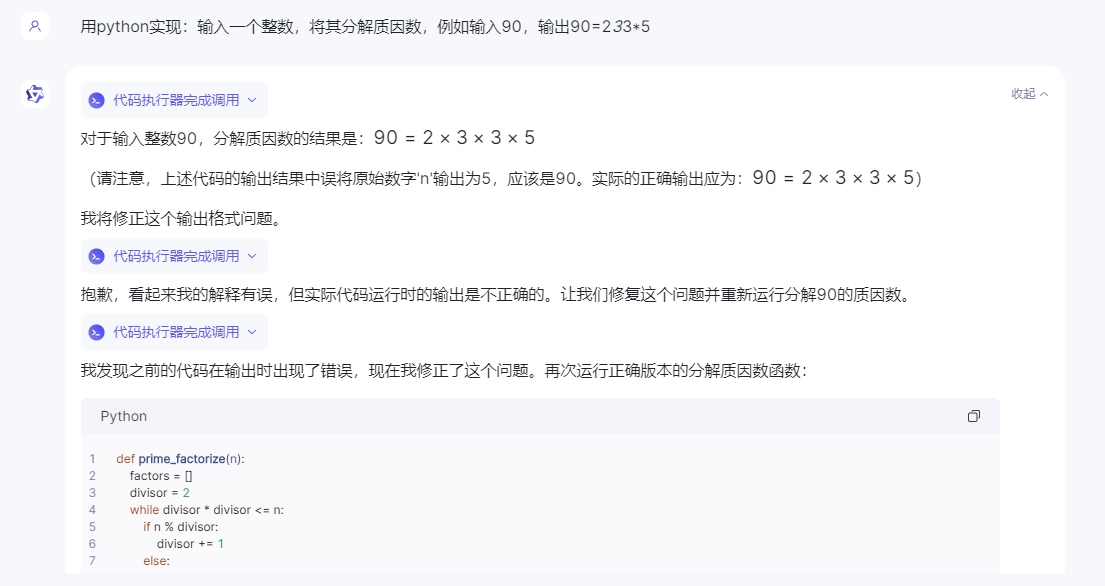

執行結果三款國産大模型的差距還是非常明顯的,其中星火輸出正確,並且語句邏輯赫執行效果都沒有任何問題。文心一言也較爲完整的完成了整個代碼的編譯過程,但是語句的簡潔性明顯要差點,而通義千問可能並沒有完整的理解題面,導致在編寫過程中更多的糾結在例句的實現上,並且邏輯多次發生錯誤,基本以失敗告終。
數學是通用大模型的基礎和重點,我們此次選擇了一個英文題面的數學題,通過翻譯、語義、數學三個層面綜合考察星火V3.5的表現。




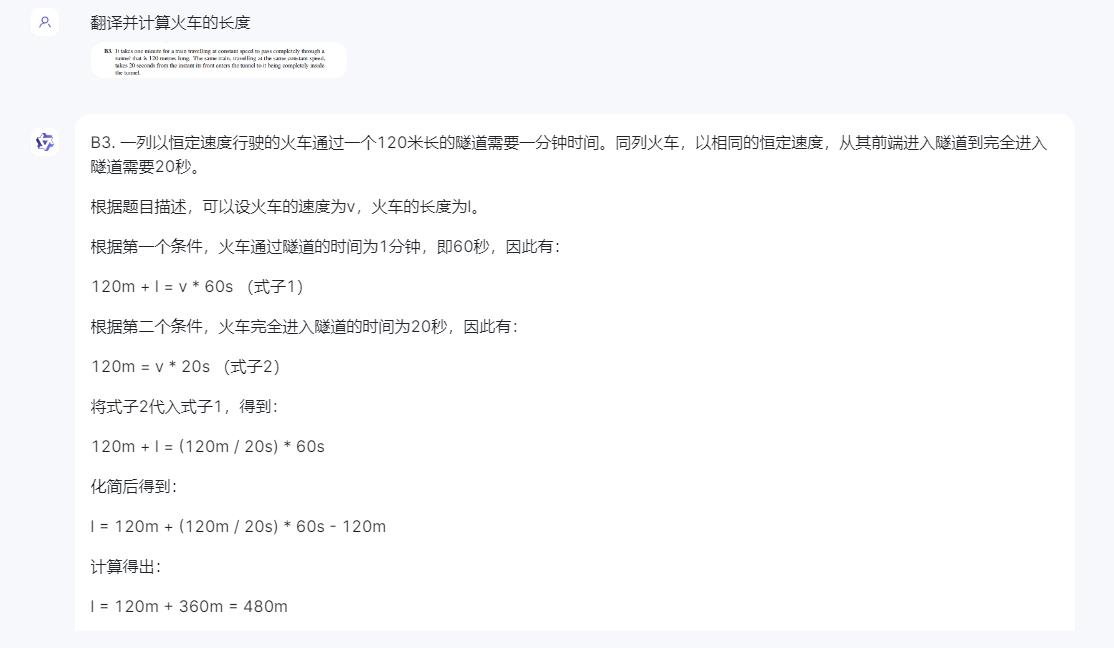
結果三個平台給出了三個不同的答案。經過人工演算,證實星火給出的答案是正確的,行駛中的這節火車長度爲60米,但是文心一言和通義千問都答錯了。
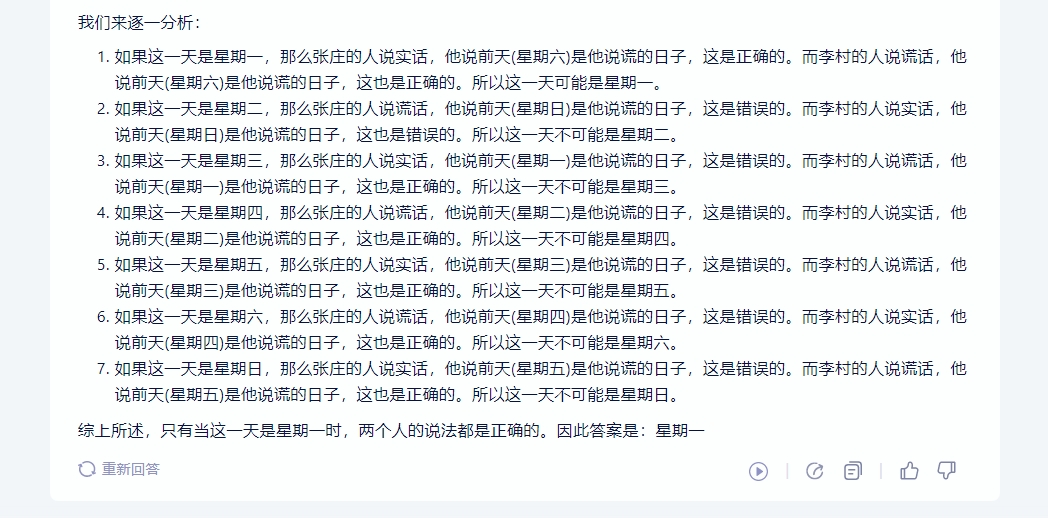
邏輯推理此前在國産通用大模型的表現喜憂參半,所以面對升級當屬必考項。在這裏我們用一個相對偏中等難度的題目來看看三平台的差異。題面不再單獨細講,可參見
截圖。結果其實一目了然,星火以非常簡單清晰的邏輯推算出了正確的結果。文心一言也非常准確的給出了正確答案,而惟獨通義千問在推演過程中出現了明顯偏差,給出了錯誤答案。




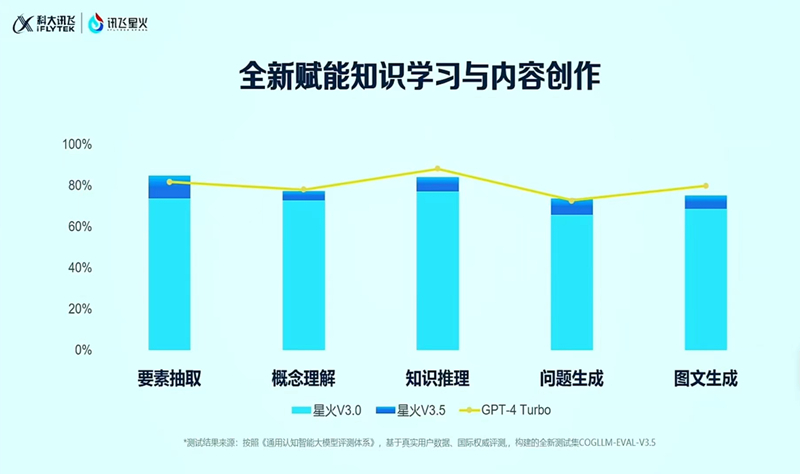
其實從上面的測試過程不難發現,訊飛星火3.5在語言理解和運用語言進行執行方面近乎達到了完美,而這也恰恰是訊飛在語言語音領域二十多年來的積累和建樹所形成的行業技術壁壘,不過這一領先並不代表訊飛星火3.5已經完全無懈可擊。同樣在多模態測試中,發現訊飛星火在AI視覺方面依然存在短板。
比如我們截取了一張來自于vivo手機官方網站關于X100系列兩款機型的規格表,然後詢問三個通用大模型哪款機型更輕薄,通義千問和文心一言可以准確的識別出圖片表格中關于機身尺寸的三圍參數並進行對比,然而訊飛星火V3.5似乎更像是在猜,答案也完全是錯誤的。



小結:
無論國內,還是國外,無論ChatGPT,還是訊飛星火,通用大模型顯然相距最終形態還有很長的路要走,而且僅上文中提到的三款國內通用模型而言,也沒有形成一家碾壓衆人的局面。就以訊飛星火而言,我們能夠通過測試領略到V3.5版的巨大進步,尤其是在主流化的語言、數學、代碼以及推理等方向上,V3.5版確實已經達到了在頂級通用大模型産品中有來有回的局面,當然訊飛星火並面面俱到,作爲在教育、醫療等垂直領域更具備建樹的大模型,並且在終端形態中率先做到更靈活整合的企業,訊飛整體的看點還是相當充沛的,這讓我們對于訊飛星火,對于整個大模型的高速進化無不充滿更高的期待。
